▶ proc freq
proc freq 결과의 내용은 간단하지만 데이터의 파악을 위해서 매우 자주 이용되는 명령문이다.
데이터의 수가 많은 경우 분포와 이상값등을 직관적으로 판단하기에 유용하다.
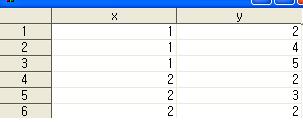
예제를 보면 개체가 많지 않기 때문에 x변수에 1이 3개, 2가 3개 인것을 볼 수 있다. 하지만 데이터가 큰 경우 하나하나 카운트 할 수 없기 때문에 proc freq를 이용한다.
data a1;
input x y @@;
cards;
1 2 1 4 1 5
2 2 2 3 2 2
;
run;
proc freq data=a1 ; 데이터셋명
tables y; 확인해보고 싶은 변수명
run;
기본적으로 하나의 변수 값(y 변수 값)에 대한 빈도를 보고 싶은 경우는 다음과 같이 명령어를 사용하며 결과창에 아래와 같은 결과로 보여지게 된다.
FREQ 프로시저
누적 누적
y 빈도 백분율 빈도 백분율
---------------------------------------------
2 3 50.00 3 50.00
3 1 16.67 4 66.67
4 1 16.67 5 83.33
5 1 16.67 6 100.00
proc freq의 내용을 데이터셋으로 저장하고 싶은 경우는
a1데이터 셋의 y변수의 빈도를 a2에 데이터셋으로 생성한 내용이다.
noprint는 a2라는 데이터셋에 결과값을 저장하였기 때문에 결과창에 프린트 되는 내용을 보여주지 않아도 된다는 옵션이다.
* 옵션
missing : 결측값을 개체로 보여준다. (missing을 사용하지 않을 경우 결측값이 있으면 출력결과에서 결측치의 수로 따로 보여지긴 하나 데이터에서는 의미있는 값으로 여기지 않는다. missing을 사용하였을때에는 결측값을 데이터의 값으로 여긴다.)
format= formatname : 테이블셀의 형식을 지정
expected : 기대빈도를 프린트
deviation : 실제빈도
cellchi2 : 2바이2 테이블에서 카이제곱값을 나타냄
cumcol : 각 cell의 누적행 퍼센트를 프린트
nocol, norow, nopercent : 결과창의 다음의 값을 출력하지 않음
proc freq data= a1;
tables y / out=a2 noprint;
run;
생성된 데이터셋은 실행해보고 확인해보기 바란다.
또한 아래와 같이 사용하면 x와 y의 교차표로 빈도를 보여준다.
proc freq data= a1;
tables x*y;
run;
출처: http://blog.naver.com/hur_yoon/
'IT > SQL' 카테고리의 다른 글
| [오라클] ORA-22992: 원격 테이블로 부터 선택된 LOB 위치를 사용할 수 없습니다. (0) | 2017.07.22 |
|---|---|
| 2016 SAS-QA사례집( SAS-KOREA) (0) | 2017.05.24 |
| [SAS] proc rank (0) | 2017.03.23 |
| [SAS] proc transpose (0) | 2017.03.23 |
| [SAS] proc sort (0) | 2017.03.23 |
| [SAS] proc compare (0) | 2017.03.23 |
| [SAS] Retain 문 (0) | 2017.03.23 |