▶ proc sort
데이터셋을 지정한 변수로 정렬하는데 이용한다. sas의 data step문에서 자주 사용하는 명령어 중 하나이다.
proc sort 는 항상 by문과 함께 사용된다.
숫자는 missing, 음수, 영, 양수의 순으로 정렬하며
문자는 아래의 순서로 정렬한다.
빈칸 ! # $ % & * + - . / 0 1 2 3 4 5 6 7 8 9 : ; < = > ? @
ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]_
abcdefghijklmnopqrstuvwxyz{/}~
다음 데이터 셋에 proc sort를 해보자.
data a;
input a b @@;
cards;
2 1 3 1 4 1 5 1 2 2 2 3 1 1 4 2 5 2 6 1
;
run;
proc sort data= a out=b;
by a;
run;
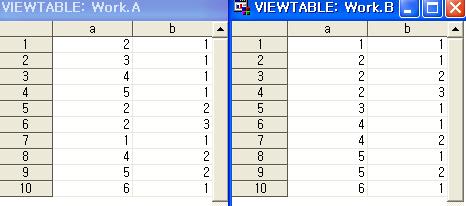
정렬된 내용을 보면 a변수로 정렬하도록 지정하였으며
out에 b에 정렬된 데이터셋을 저장하라고 지정한 것이다. out이 없는 경우 a 데이터셋에 정렬된다.
기본적으로 sort는 오름차순으로 정렬된다.
또한 같은 수가 있는 경우는 정렬 전 데이터에서 상위에 있는 데이터가 먼저 나오게 된다.
[정렬하기 전 데이터 셋] [정렬 후 데이터 셋]
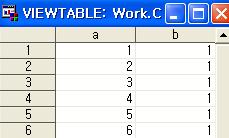
proc sort의 또하나의 기능은 중복을 제거할 수 있다.
proc sort data= a out=c nodupkey;
by a;
run;
다음과 같이 nodupkey를 이용하며 a변수값의 중복을 제거할 수 있다. 이때 주의할 점은 위의 정렬 경우와 마찬가지로 같은 값이 있을때 정렬 전 상위에 있는 값만 남게되고 아래 값들이 제거된다.
* 반대로 내림차순으로 정렬하고 싶은 경우는 descending 옵션을 사용하면 된다.
proc sort data= a out=d;
by descending a;
run;
출처: http://blog.naver.com/hur_yoon/
'IT > SQL' 카테고리의 다른 글
| [SAS] proc rank (0) | 2017.03.23 |
|---|---|
| [SAS] proc freq (0) | 2017.03.23 |
| [SAS] proc transpose (0) | 2017.03.23 |
| [SAS] proc compare (0) | 2017.03.23 |
| [SAS] Retain 문 (0) | 2017.03.23 |
| [SAS] Format 문 / Informat 문 (0) | 2017.03.23 |
| [SAS] do ~ end, stop 명령문 (0) | 2017.03.23 |