그러나 절대 그렇지 않습니다. 오라클에도 개인용 버전이 있으며 개인이 무료로 다운로드하여 '교육'적인 목적으로 사용하는 데에는 전혀 제약이 없습니다. 기업용도 무료로 다운로드하여 실습을 할 수 있습니다. 그리고 데이터베이스의 만국 공통어인 SQL을 직접 다뤄봄으로써 데이터베이스의 기초를 확실히 다질 수 있습니다.
겁먹지 마시고 부담갖지 마시고 이제부터 오라클, 아니 정확하게 말하면 SQL 기초 과정을 본격적으로 시작합니다.
그러려면 먼저 오라클이 어떻게 생겼는지, 설치부터 해봐야죠.
오라클 소프트웨어를 다운로드하려면 우선 OTN에 가입을 해야합니다.
OTN은 Oracle Technology Network의 약어입니다.
OTN의 한국어 사이트는 http://otn.oracle.co.kr 영문 사이트는 http://otn.oracle.com입니다.
소프트웨어 다운로드뿐만 아니라 각종 기술적인 문제들까지 이곳을 참고하여 해결할 수 있습니다.
- 먼저 다운로드를 위한 회원 가입을 합니다. 다운로드는 영문 사이트에서만 가능하므로 영문 오라클 사이트에서 가입합니다.
- 회원 가입 페이지로 바로 가기
- sign me up!을 클릭해 회원 가입을 합니다.
- 회원 가입 페이지로 바로 가기
- 오라클 개인용 버전(Personal Edition)을 다운로드하기 위해 OTN 사이트로 이동을 합니다. (한국어 사이트도 구경할 겸 한국어 사이트로 이동해 봅니다.)
OTN 사이트로 바로가기 - 왼쪽 메뉴에서 다운로드를 클릭한 다음
- 아래 Select a Product에서 8i Personal Database를 선택합니다.
- 위에서 회원에 가입하신 분은 ID와 Password를 입력하고 그렇지 않은 분은 회원 가입부터합니다.
- Oracle8i Personal Edition의 Windows 2000이나 Windows 98 중 하나를 선택합니다.
오라클은 현재 Windows ME 버전은 없다고 합니다. - ELIGIBILITY EXPORT RESTRICTIONS의 다섯 개의 선택 항목을 모두 체크하고 하단의 [I Accept]를 클릭합니다.
- 그런데 조금 자존심이 상합니다. 첫번째 선택란의 내용을 읽어보면 대충 "나는 미국의 수출 금지 지역인 쿠바, 이란, 북한의 국민이 아니다"라는 뜻이죠. 게다가 두번째 항목에서 "나는 위에서 언급한 나라에 직간접적으로 프로그램을 팔지 않는다"... 쩝~
- 원하는 파일을 클릭하여 다운로드합니다.
Windows98용은 약 280MB, Windows2000용은 610MB 정도 됩니다. 장난 아니죠? 다운로드하려면 두루넷과 같은 초고속 전용선이 있더라도 족히 1~2시간은 걸릴 것입니다.
다운로드하려면 시간이 많이 걸리겠군요.
그럼 설치는 다음 시간에 하죠...
다운로드 다 했죠? 그리고 적절한 폴더에 일단 압축을 풀고 Setup 파일을 더블클릭합니다. 여기까지는 하실 줄 아시죠?
가정에 CD Writer(요즘은 R/W) 있으시면 CD로 구워놓으셔도 됩니다. 그러면 CD롬 드라이브에 넣으면 자동 실행됩니다.
그럼 설치를 시작해보겠습니다.
아래 그림은 Windows 98에서 설치한 상태인데 Windows2000에서도 동일한 화면이 나타납니다.
그런데 Windows2000에서 설치가 잘 안되는 분들이 많으신가 봅니다.
OTN Forum에 MS Windows용 Oracle 설치 관련 포럼이 있습니다. 거기에 보면 Windows 2000 설치 관련 오류 뿐만 아니라 각종 설치 문제 해결하는 방법이 나와 있습니다.
저도 Windows2000에 설치할 때 설치가 진행되지 않았는데 원인은 PentiumIV CPU에 있었습니다.(CPU 잘못이라는 말이 아니라 P IV CPU에서 오류가 난다는 말씀) PentiumIV에 설치할 때 오류가 나는 문제를 이 사이트를 통해 해결하였습니다. 만약 동일한 문제가 나타나시는 분이라면 여기를 클릭해서 해결하세요...
아래와 같은 설치 화면만 정상적으로 나타난다면 아무런 문제가 없습니다. 그냥 화면을 보고 기본 설정 상태로 진행하면 됩니다.
단 설치 과정 중에서 오라클 "데이터베이스 이름"과 "식별자(SID)"를 입력하는 과정이 있는데, 고민하지 마시고 그냥 기억하기 쉬운 것으로 입력하세요.
교육용이니까 "EDU"라고 해도 되고, 저는 제 이름의 이니셜을 따서 "SBM"이라고 했습니다.
직접 설치해보시구요... 참고 삼아 설치 화면 몇 장면을 보여드리겠습니다.
다 설치 되었죠?
그럼 다음 시간부터 SQL*Plus라는 오라클 툴을 이용하여 SQL 명령문을 하나하나 실습해 보기로 하죠.
오라클 설치까지 모두 끝나셨죠? 수고하셨습니다.
오늘부터는 본격적으로 오라클을 사용한 SQL 실습을 하기로 하겠습니다.
- SQL이란?
SQL은 Structred Query Language의 약어이입니다. 우리말로 흔히 "구조적 질의어"라고 풀이하는데, 쉽지 않은 표현입니다.
그러나 달리 표현할 말이 없기에 그냥 SQL이라고 부릅니다.
SQL은 데이터베이스에서 정보를 얻거나 갱신하기 위한 표준화된 언어를 말합니다. 오늘부터 실습할 SQL*Plus와 같은 툴에서 대화형으로 이용할 수도 있고 프로그램 내에 삽입하여 사용할 수 있습니다.(이 홈페이지의 데이터베이스는 MySQL을 사용하였는데 역시 오라클과 같이 SQL을 사용하는 데이터베이스의 한 종류입니다.)
보통 그냥 SQL이라고 하면 ANSI와 ISO의 표준 언어를 말합니다.
SQL 표준에 관한 홈페이지도 있습니다. 궁금하시면 여기를 클릭해보세요.(영문 사이트입니다.)
참고로 PL/SQL이라는 것은 오라클 DBMS에서 사용되는 오라클 프로그래밍 언어를 말합니다.
그럼 우리는 지금 오라클을 학습합니까, 아니면 SQL을 학습합니까라고 묻는 분도 계실 것 같은데, 대답은 둘 다입니다.
우리는 오라클 서버(DBMS)와의 통신을 위해 SQL이라는 언어를 사용합니다. 즉 데이터베이스의 전반적인 개념 습득과 SQL 문장의 기본을 익히기 위해 오라클이라는 데이터베이스 프로그램을 이용하는 것입니다.
그런 다음 오라클이든 MS-SQL이든, MySQL이든 보다 고급적인 과정을 학습하고 싶으시다면........... 두툼한 전문 서적을 사 보세요.^^ - SQL*Plus
SQL*Plus는 SQL과 PL/SQL 문장을 인식하여 실행시켜 주며 SQL을 실행하는 환경을 제공하는 오라클 툴입니다. 즉 오라클에서 데이터베이스를 SQL로 관리할 수 있도록 해주는 또 하나의 프로그램입니다. - SQL 명령어의 종류
위에서 SQL은 데이터베이스를 조작하기 위한 언어라는 것을 알았습니다.
데이터베이스를 조작하기 위해서는 여러 명령어들이 필요한데 일반적으로 다음과 같이 분류합니다.
RETRIEVE는 데이터 검색하는 목적으로 사용되며 SELECT 명령이 있습니다.
DML은 데이터 조작어라고 부르며 데이터를 삭제, 수정, 삽입할 때 사용합니다.
RETRIEVE도 결국 DML에 속하는 것인데 워낙 자주 쓰이는 명령이라 여기서는 별도로 분류했습니다.
그 외에 데이터의 구조를 만들고 바꾸는 DDL과 DB에 접근하는 권한 설정과 관련된 DCL 등이 있습니다.
여기서는 대체적으로 이러한 명령어 부류가 있다는 것만 이해하시고 넘어가셔도 될 것입니다. 대표적인 명령어에 대해서는 추후 하나씩 실습을 할 예정입니다. - SQL*Plus 실행
위에 그림에 다 나와있죠?
경로가 좀 복잡하지만 [시작]-[프로그램]-[Oracle - OraHome81]-[Application Development]-[SQL Plus]를 실행하면 됩니다.
다짜고짜 사용자 이름과 암호를 입력하라고 합니다.
사용자 이름에는 scott, 암호는 tiger를 입력하고 [확인]을 누르세요.
scott와 tiger를 등록한 적이 없다구요? 이건 오라클에서 기본적으로 제공하는 ID와 패스워드입니다. 이건 보통 End User용으로 사용되고 시스템 관리자용으로는 ID:system PW:manager를 사용합니다.
바로 이 창이 앞으로 실습하게 될 SQL*Plus 실행 창입니다. 여기에 각종 SQL 명령을 입력하고 그 결과를 확인하는 과정을 거치게 될 것입니다.
아쉽지만 본격적인 SQL 문장은 다음 시간에 다루기로 하죠.
참, 창을 닫아야 되네요.
SQL*Plus를 종료하려면 exit를 입력하고 [Enter]
됐죠?
지난 시간에 SQL*Plus를 기동하고 종료해봤습니다. 이 시간에는 SQL*Plus에서 직접 명령어를 입력하고 잘못된 명령어를 수정하는 등 기초적인 SQL*Plus 사용법에 대해 실습할 예정입니다.
먼저 SQL*Plus를 실행합니다.
다음과 같이 SQL>가 보이면 정상입니다.
- 명령어 입력
아래와 같이 입력하고 그 결과가 보이는지 확인해 봅시다.
SELECT *
FROM TAB; 만 입력하시고 Enter를 치시면 됩니다.
FROM TAB; 앞에 숫자 2는 2행이라는 뜻으로 자동 생성됩니다. 입력하는 것이 아닙니다.
나타나는 결과는 여러분들과 조금 다를 수가 있습니다. 그러나 TNAME과 TABTYPE, CLUSTERID 등 위와 비슷하게 보이면 정상입니다.
FROM TAB뒤에 ;는 명령어의 끝이라는 표시입니다.
- SQL 문에서는 원칙적으로 문장의 끝에 ;를 표시하도록 하고 있습니다. 그러나 SQL*Plus에서는 생략해도 실행이 됩니다. 그렇지만 습관은 초기에 들이기 나릅입니다. 표준 SQL에 근거하여(다른 데이터베이스 프로그램에서도 실수 없이 사용하기 위해) 문장의 끝에 ;를 꼭 표시하는 습관을 들이도록 합시다.
- SQL 문장은 여러 행에 걸쳐서 사용할 수 있습니다. 위에서는 2행에 걸쳐 하나의 문장을 입력한 것입니다. 그리고 그 끝을 알리는 ; 표시를 한 것이죠.
- SQL 문장은 대문자와 소문자를 구분하지 않습니다. 위의 내용을
select * from tab;이라고 해도 실행이 됩니다. 그러나 SQL 문장만 대소문자를 구분하지 않는 것이지 데이터를 검색할 때는 대소문자를 가려 써야합니다. 예를 들어 데이터 중에서 "SBM"를 찾아라와 "sbm"을 찾아라는 것은 명백히 다르다는 것입니다.
- SQL 문에서는 원칙적으로 문장의 끝에 ;를 표시하도록 하고 있습니다. 그러나 SQL*Plus에서는 생략해도 실행이 됩니다. 그렇지만 습관은 초기에 들이기 나릅입니다. 표준 SQL에 근거하여(다른 데이터베이스 프로그램에서도 실수 없이 사용하기 위해) 문장의 끝에 ;를 꼭 표시하는 습관을 들이도록 합시다.
- 잘못된 문장의 수정
이번에는 조금 다르게 입력해 보죠.
SELECT *
FORM TAB;
FROM을 FORM으로 일부러 틀리게 입력 해보세요.
2행에 오류가 발생했다는 메시지가 나타나죠.
계속해서 아래와 같이 명령을 입력해 보세요. 빨간색 밑줄 친 부분이 실제 입력하는 부분입니다.
- ①의 L 명령어는 LIST 명령과 동일합니다. 방금 입력한 SQL 문장을 출력하라는 뜻입니다.
- ②의 C 명령어는 문장을 수정하는 것입니다. C/FORM/FROM은 FORM을 FROM으로 수정하라는 뜻입니다. 그런데 수정할 수 있는 행은 L 명령을 실행했을 때 행번호 뒤에 * 표시가 있는 행입니다. 만약 제1행의 SELECT를 SELECT COUNT(*)로 수정하고 싶다면
L1
C/*/COUNT(*)와 같이 하면 됩니다. - ③의 RUN 명령은 지금 버퍼에 있는 문장을 실행하라는 뜻입니다. ②에서 SQL 문장을 일부 수정하였으니 수정한 상태로 다시 실행하라는 뜻이죠. RUN 대신에 그냥 슬래쉬(/)만 써도 됩니다. RUN 명령은 버퍼에 있는 문장을 한번 출력하고 난 다음에 결과를 보여주고, 슬래쉬(/)는 SQL 문장을 보여주지 않고 그냥 결과만 보여줍니다.(직접 한번 해보세요.)
- ①의 L 명령어는 LIST 명령과 동일합니다. 방금 입력한 SQL 문장을 출력하라는 뜻입니다.
- SQL*Plus Command
위에서 몇 가지 SQL*Plus 명령을 실습해 봤습니다.
SQL*Plus에서 사용할 수 있는 명령은 다음과 같습니다.
주의하실 것은 아래의 명령은 SQL*Plus에서 명령어를 편집하고 저장, 실행하는 등 SQL*Plus라는 SQL을 사용하기 위한 오라클 툴에서의 명령어입니다. 다음 시간부터 다룰 SQL 명령(문장)이 아닙니다. SQL 문장은 데이터베이스를 조작 검색하기 위한 표준화된 언어를 말합니다.
- SQL*Plus에서의 편집 관련 명령어
- 그 외 명령어
- SQL*Plus에서의 편집 관련 명령어
다음 시간부터는 SQL 명령어(문장)을 통해 데이터를 검색하고 조작하는 실습을 하겠습니다.
이번 시간에는 SQL 문 중에서 가장 많이 사용되는 명령어인 SELECT 명령어의 사용법에 대해 알아보겠습니다.
- 형식
SELECT 명령은 데이터베이스에서 데이터를 검색할 때 사용하는 것으로 아래와 같은 형식으로 사용됩니다.
여기서 INTO와 관련된 실습은 하지 않습니다. INTO는 검색 결과를 특정 변수에 저장하는 것인데 SQL을 이용하여 다른 프로그래밍을 할 때 사용됩니다. 따라서 INTO와 관련해서는 다른 프로그래밍 언어에서 실습하면 되고 여기서는 실습을 생략합니다. - SQL 명령어 작성법
앞 강좌에서 이미 일부는 설명을 했었는데 자세히 살펴보죠.
- SQL 문장은 여러 줄에 걸쳐 입력할 수 있습니다.
- 그리고 입력할 때는 되도록 SQL 명령어는 읽기 쉽도록 들여쓰기를 하고
- SELECT, FROM, WHERE는 각기 다른 Line에 적는 것이 좋습니다. 그래야 한눈에 들어오니까요.
- SQL 명령어는 대소문자를 구분하지 않습니다.
- SQL 문장의 끝은 세미콜론(;)으로 종료합니다.
- SQL 문장은 여러 줄에 걸쳐 입력할 수 있습니다.
- 실습용 Sample 테이블 작성
우리는 앞으로의 실습을 위해 몇 개의 테이블을 만들어야 되는데 우선 첫번째로 다음과 같은 EMP 테이블을 만들 것입니다.
그런데 오라클을 설치하면 기본적으로 EMP 테이블이 있습니다. 따라서 아래와 같이 DROP 명령을 줘서 기존의 EMP 테이블을 지우고, CREATE 명령으로 새롭게 EMP 테이블을 만들어, INSERT를 사용하여 테이블에 데이터를 입력합니다.
DROP, CREATE, INSERT 등의 명령에 관해서는 후에 SELECT와 관련된 모든 실습이 끝난 후에 다룰 예정이므로 아래의 문장을 그냥 입력하시기만 하면 됩니다.
만약 입력하시기가 어렵다면 아래의 문장을 그대로 복사하여 SQL*Plus에 붙여넣기를 해도 됩니다.
SQL*Plus를 실행하여 다음 내용을 직접 입력하거나 복사하여 붙여넣으세요.
DROP TABLE EMP;
CREATE TABLE EMP (
EMP_NUM CHAR(5) PRIMARY KEY,
LAST_NAME VARCHAR2(30) NOT NULL,
FIRST_NAME VARCHAR2(30) NOT NULL,
JOB_CODE CHAR(2) NOT NULL,
ADDRESS VARCHAR2(100) );
INSERT INTO EMP VALUES ( '10001', 'GRANT', 'LINDA', 'PE', '34 of 1st Street');
INSERT INTO EMP VALUES ( '10002', 'AMY', 'JONATHAN', 'PS', '200 Rose Street');
INSERT INTO EMP VALUES ( '10003', 'HUROW', 'LILY', 'SS', '101 Bear Town');
INSERT INTO EMP VALUES ( '10004', 'ADAM', 'EVELY', 'CS', '202 Declaration Drive');
INSERT INTO EMP VALUES ( '10005', 'JULIE', 'ROSE', 'PE', '788 McTyne Street');
INSERT INTO EMP VALUES ( '10006', 'ALBERT', 'MAY', 'SS', '320 Elaine Ave');
INSERT INTO EMP VALUES ( '10007', 'AMY', 'KENT', 'SS', '829 Cerritos Ave');
위와 같은 방법으로 다음과 같은 VIDEO 테이블을 만들어 봅시다.
DROP TABLE VIDEO;
CREATE TABLE VIDEO (
VIDEO_NO CHAR(3) PRIMARY KEY,
VIDEO_NAME VARCHAR2(30) NOT NULL,
PLAY_TIME NUMBER NOT NULL,
DESCRIPTION VARCHAR2(100) NOT NULL );
INSERT INTO VIDEO VALUES ('101', 'LAMBO', 150, 'ACTION IN WAR GAME');
INSERT INTO VIDEO VALUES ('201', 'TOW CAPS', 100, 'HUMOROUS STORIES OF CAPS');
INSERT INTO VIDEO VALUES ('260', 'THE LOVER', 150, 'LOVE STORIES IN ASIAN WAR');
INSERT INTO VIDEO VALUES ('340', 'STING', 100, 'THRILLER AND HOT MOVIE');
INSERT INTO VIDEO VALUES ('390', 'ROMEO AND JULIET', 200, 'SAD LOVE STORY OF TWO LOVERS');
INSERT INTO VIDEO VALUES ('401', 'SPEED', 200, 'SPEED ACTION WITH A TRAILOR BUS');
INSERT INTO VIDEO VALUES ('500', 'POWER OF LOVE', 100, 'POWER OF LOVE');
INSERT INTO VIDEO VALUES ('560', 'CINEMA PARADISE', 150, 'MOVIE OF LOVE'); - 간단한 SELECT 쿼리 실습
아래의 구체적인 실습 예를 통해 SELECT~FROM~WHERE; 문장의 사용법을 익히시기 바랍니다.
SQL*Plus를 실행하여 다음 내용을 직접 입력해 보세요.
- EMP 테이블에서 LAST_NAME이 AMY인 모든 Data를 검색하려면
SELECT *
FROM EMP
WHERE LAST_NAME = 'AMY' ;
여기서 주의하실 것은 문자열을 표시할 때 큰 따옴표(" ")가 아니라 작은 따옴표(' ')로 둘러싸야 합니다.
SQL에서는 검색을 위한 식을 입력할 때 숫자형 데이터만 그대로 표시하고 문자형 데이터나 날짜형 데이터는 작은 따옴표로 묶어야 합니다. - EMP 테이블에서 JOB_CODE가 SS인 Data의 EMP_NUM, LAST_NAME, FIRST_NAME 칼럼만 표시하려면
SELECT EMP_NUM,
LAST_NAME,
FIRST_NAME
FROM EMP
WHERE JOB_CODE = 'SS' ;
쉼표 여부를 주의해서 입력하셔야 됩니다. FIRST_NAME 뒤에는 쉼표가 없습니다. - WHERE 조건 절에서 특정 데이터를 지정하는 것이 아니라 컬럼 이름으로 조건을 지정할 수도 있습니다. 예를 들어 VIDEO 테이블에서 VIDEO_NAME이라는 컬럼(필드)과 DESCRIPTION이라는 컬럼의 내용이 일치하는 행의 VIDEO_NO만 표시하라고 한다면,
SELECT VIDEO_NO
FROM VIDEO
WHERE VIDEO_NAME = DESCRIPTION;와 같이 쓰면 됩니다. - WHERE 조건 절에서 비교 연산자를 이용해서 조건을 입력해도 됩니다. 예를 들어 VIDOE 테이블에서 PLAY_TIME이 2시간 이상인 행의 VIDEO_NO를 표시하려면,
SELECT VIDEO_NO
FROM VIDEO
WHERE (PLAY_TIME / 60) > 2;
- EMP 테이블에서 LAST_NAME이 AMY인 모든 Data를 검색하려면
- 비교 연산자
SQL에서 사용 가능한 비교 연산자는 다음과 같습니다.
같다(=), 같지 않다(!= 또는 <>), 작다(<), 크다(>), 작거나 같다(<=), 크거나 같다(>=)
주의할 것은 같지 않다를 NOT= 과 같이 표시해서는 안됩니다. - AND, OR operator
AND와 OR는 상식적인 선에서 이해를 하시면 됩니다.
- AND는 AND를 중심으로 좌우의 조건이 모두 만족할 경우에 참이 됩니다.
- OR는 OR를 중심으로 좌우의 조건 중 어느 하나라도 만족할 경우 참이 됩니다.
- 하나의 SELECT 문에서 여러 개의 AND 또는 OR를 사용할 수 있습니다.
- AND는 AND를 중심으로 좌우의 조건이 모두 만족할 경우에 참이 됩니다.
- 컬럼 별명(Column Alias)
컬럼 별명은 검색 결과가 화면에 표시될 때 컬럼 제목을 원하는 형태로 출력하고자 할 때 사용합니다.
SELECT VIDEO_NO (AS) "NUMBER" ,
VIDEO_NAME (AS) "Video Name"
FROM VIDEO
WHER PLAY_TIME > 150;
위의 예에서 AS를 괄호로 표시한 것은 AS를 생략할 수 있다는 것입니다. AS를 쓰거나 아니면 입력하지 마세요. (AS)와 같은 식으로 입력하면 안됩니다. - 연결 연산자
위의 Column Alias를 이해하셨다면 설명보다는 아래의 문장을 직접 실행해 비교해 보세요.
- SELECT EMP_NUM,
LAST_NAME || ' ' || FIRST_NAME "NAME"
FROM EMP
WHERE JOB_CODE = 'SS' ; - SELECT EMP_NUM,
LAST_NAME, FIRST_NAME
FROM EMP
WHERE JOB_CODE = 'SS' ;
첫번째 예제는 LAST_NAME과 FIRST_NAME 사이를 한 칸 띄고 연결하여 "NAME"이라는 새로운 이름의 컬럼 제목으로 출력하는 것입니다. 단지 알아보기 쉽도록 그렇게 표시하라는 뜻입니다. 실제 컬럼의 제목이 바뀐 것은 아닙니다. - SELECT EMP_NUM,
내용이 좀 많았네요.
이번 시간에는 데이터 검색을 위한 몇 가지 Keywords에 대해 실습해 보겠습니다. 오라클에서 데이터 검색을 할 때 사용되는 Keywords에는 조건문의 부정을 나타내는 NOT, 특정 값의 범위를 지정하는 BETWEEN, OR 연산자와 비슷한 IN, 와일드 카드를 사용할 수 있는 LIKE, 널 값을 찾을 때 쓰는 IS NULL, 중복된 열을 가려내는 DISTINCT 등이 있습니다.
- NOT
- 이름에서 드러나듯이 NOT은 조건문의 부정을 표현할 때 사용합니다.
- NOT은 바로 뒤에 오는 조건문 하나에만 적용됩니다.
- NOT의 위치는 주로 Column Name 앞에 오게 됩니다.
- NOT이 AND와 OR와 함께 사용된 경우 NOT은 바로 뒤의 조건 하나에만 적용된다. 만약 여러 조건에 적용하려면 괄호로 묶어주면 됩니다.
- "NOT ="와 같이 쓰면 문법 오류(Syntax Error)가 발생합니다.
- 예를 하나 들어 볼까요...EMP테이블에서 JOB_CODE가 'SS'가 아닌 ROW의 LAST_NAME, JOB_CODE를 표시하려 한다면...
SELECT EMP_NUM, LAST_NAME, JOB_CODE
FROM EMP
WHERE NOT JOB_CODE = 'SS' ; - AND나 OR 연산자를 사용할 경우를 한번 볼까요?
SELECT EMP_NUM, LAST_NAME, JOB_CODE
FROM EMP
WHERE NOT JOB_CODE = 'SS'
AND EMP_NUM >= '10002'; - 위와 비슷한 예제인데 다음과 같이 NOT 뒤의 문장을 괄호로 묶으면 어떨까요? 직접 실행해서 바로 위의 예제와 결과가 어떻게 다른지 한번 알아보세요.
SELECT EMP_NUM, LAST_NAME, JOB_CODE
FROM EMP
WHERE NOT (JOB_CODE = 'SS'
AND EMP_NUM >= '10002');
- 이름에서 드러나듯이 NOT은 조건문의 부정을 표현할 때 사용합니다.
- BETWEEN
- 조건문에서 특정 값의 범위를 지정할 때 사용합니다.
- 최소값을 AND의 왼쪽에, 최대값을 오른쪽에 표기합니다.
- 최소값과 최대값은 자신을 포함합니다.
- BETWEEN을 부정하려면 아래와 같은 2가지 방법으로 가능합니다.(NOT의 위치를 잘 보세요.)
- WHERE EMP_NUM NOT BETWEEN '10001' AND '99999'
- WHERE NOT EMP_NUM BETWEEN '10001' AND '99999'
- WHERE EMP_NUM NOT BETWEEN '10001' AND '99999'
- 직접 실습해 봅시다.
SELECT EMP_NUM, LAST_NAME
FROM EMP
WHERE EMP_NUM BETWEEN '10003' AND '10005';
결과가 예측이 되겠지만 직접 한번 입력해 보세요.
위 문장의 마지막 줄은 다음과 같이 바꿔 써도 됩니다.
WHERE EMP_NUM >= '10003' AND EMP_NUM <= '10005';
- 조건문에서 특정 값의 범위를 지정할 때 사용합니다.
- IN
- 컬럼(필드)의 값이 괄호 안의 List 값에 해당하는 경우 해당 행(레코드)를 돌려줍니다.
- 결국 IN은 OR 논리 연산자로 바꿔서 표현할 수 있습니다.
- IN의 부정은 아래의 두 가지 방법이 있습니다.(IN의 위치를 주목하세요.)
- WHERE JOB_CODE NOT IN ('PE', 'PS', 'CS')
- WHERE NOT JOB_CODE IN ('PE', 'PS', 'CS')
- 위의 문장은 결국 이렇게 됩니다.
WHERE JOB_CODE != 'PE' AND JOB_CODE != 'PS' AND JOB_CODE != 'CS'
- WHERE JOB_CODE NOT IN ('PE', 'PS', 'CS')
- 자, 실습해 봅시다.
SELECT *
FROM EMP
WHERE JOB_CODE IN ('PE', 'PS', 'CS');
위의 마지막 WEHRE 절을 OR 문으로 바꿔 쓰면 어떻게 될까요?
WHERE JOB_CODE = 'PE' OR JOB_CODE = 'PS' OR JOB_CODE = 'CS' - 컬럼(필드)의 값이 괄호 안의 List 값에 해당하는 경우 해당 행(레코드)를 돌려줍니다.
지난 시간에 검색을 위한 KEYWORDS 중에서 NOT, BETWEEN, IN에 대해 살펴 보았습니다. 이번 시간에는 와일드 카드를 사용할 수 있는 LIKE, 널 값을 찾을 때 쓰는 IS NULL, 중복된 열을 가려내는 DISTINCT에 대해 알아보겠습니다.
반드시 실습을 하셔야 됩니다. 그냥 읽고 넘어가시면(물론 저보다 다들 머리가 좋으니까 넘어갈 수도 있겠지만) 百見이 不如一打 - 일단 키보드로 확인하고 넘어가세요...)
- LIKE
와일드 카드 문자 아시죠? 예를 들어 도스에서 'A'로 시작하는 모든 파일이라고 하면 'A*.*'이라고 쓰죠. 도스 기반에서는(Windows에서도 마찬가지이지만) 문자 하나를 나타내는 와일드 카드 문자는 '?', 여러 문자를 나타내는 와일드 카드 문자는 '*'를 사용합니다.
원래 와일드 카드는 트럼프를 이용한 여러 가지 카드 게임에서 52장의 카드 한 벌 중 원하는 어떤 종류의 카드로도 써먹을 수 있도록 특별히 지정된 카드, 즉 만능 패를 의미합니다. 그래서 일명 만능 문자로 번역하기도 합니다.
LIKE는 와일드 카드 문자를 사용할 수 있는 키워드입니다.
- 오라클(SQL)에서 사용 가능한 와일드 카드 문자는 다음 두 종류가 있습니다.
- % : 0~여러 개의 문자를 의미합니다.
- _ (Underscore): 1개의 문자를 의미합니다.
- % : 0~여러 개의 문자를 의미합니다.
- 다음과 같이 입력하고 그 결과를 보세요.
SELECT *
FROM EMP
WHERE EMP_NUM LIKE '1%0_' ;
무슨 뜻이죠?
EMP_NUM 컬럼의 값이 '1~0□'인 것을 찾는 것이죠. 즉 1과 0 사이에는 어떠한 문자가 와도 상관없고 0 뒤에 하나의 문자가 있는 것을 의미합니다. - Like를 부정하려면 다음과 같이 사용합니다.(NOT의 위치를 잘 보세요.)
- WHERE LAST_NAME NOT LIKE 'A%'
- WHERE NOT LAST_NAME LIKE 'A%'
- WHERE LAST_NAME NOT LIKE 'A%'
- 오라클(SQL)에서 사용 가능한 와일드 카드 문자는 다음 두 종류가 있습니다.
- IS NULL
- 컬럼으 값이 Null인 Row(레코드)를 찾을 때 사용합니다.
- IS NULL을 사용할 수 있는 컬럼의 컬럼 룰은 당연히 NN(No Null)이 아니어야 겠죠.
- NULL은 0이나 스페이스(빈칸)이 아닙니다. 아무 것도 없는 값을 의미합니다. 즉 입력하지 않은 상태를 말합니다.
- NULL을 포함한 산술 연산(+,-,*,/ 등)의 결과값은 모두 NULL이 됩니다.
- IS NULL 대신 = NULL 을 사용하면 Syntax Error(문법 오류)는 아니지만 원하는 결과가 안 나옵니다. '= NULL'은 결국 문자열이 문자열 NULL과 같은 것이라는 의미가 되는데... 이렇게 쓰면 안되겠죠?
- IS NULL의 부정 표현은 다음과 같이 사용합니다.(NOT의 위치를 잘 보세요. 보통 첫째 줄처럼 IS NOT NULL과 같이 사용합니다. 영어 문법을 따른 것이죠.)
- WHERE AVAILABLE IS NOT NULL;
- WHERE NOT AVAILABLE IS NULL;
- WHERE AVAILABLE IS NOT NULL;
- IS NULL을 실습하기 위해 다음과 같은 EMP_SKILL 테이블이 필요합니다.
일단 다음과 같이 입력하여(복사해 붙여넣어도 됩니다.) 기존의 EMP_SKILL 테이블을 버리고 다음 내용의 새로운 테이블을 하나 만듭니다.
DROP TABLE EMP_SKILL;
CREATE TABLE EMP_SKILL
( EMP_NUM CHAR(5),
SKILL_NO CHAR(4),
ACQUIRE_DATE DATE NOT NULL,
AVAILABLE CHAR(3),
CONSTRAINT PK_EMPSKILL PRIMARY KEY(EMP_NUM, SKILL_NO) );
INSERT INTO EMP_SKILL VALUES ( '10001', 'S101', '99/01/20', 'YES');
INSERT INTO EMP_SKILL VALUES ( '10001', 'S102', '99/02/23', NULL);
INSERT INTO EMP_SKILL VALUES ( '10002', 'P101', '98/04/04', NULL);
INSERT INTO EMP_SKILL VALUES ( '10003', 'C101', '00/05/23', 'YES');
INSERT INTO EMP_SKILL VALUES ( '10004', 'S101', '99/07/07', NULL);
INSERT INTO EMP_SKILL VALUES ( '10004', 'P101', '99/10/11', NULL);
INSERT INTO EMP_SKILL VALUES ( '10006', 'E101', '00/12/13', NULL); - 다음과 같이 입력해서 그 결과를 살펴 보세요.
- SELECT *
FROM EMP_SKILL
WHERE AVAILABLE IS NULL; - SELECT *
FROM EMP_SKILL
WHERE AVAILABLE = NULL; - SELECT *
FROM EMP_SKILL
WHERE AVAILABLE IS NOT NULL;
- SELECT *
- 컬럼으 값이 Null인 Row(레코드)를 찾을 때 사용합니다.
- DISTINCT
- distinct는 '별개의', '~와는 종류가 다른'이라는 뜻을 가진 단어입니다.
- SQL 문에서 DISTINCT는 검색 결과(Result Set) 중에서 중복된 Row(레코드)는 한 번만 보여주도록 합니다.
- DISTINCT는 SELECT 문에서 딱 한 번만 사용할 수 있습니다.
- DISTINCT 뒤에는 여러 컬럼(필드)을 기술할 수 있는데 이때는 모든 컬럼에 DISTINCT가 적용됩니다.
- 실습을 해야 무슨 뜻인지가 정확히 이해되겠죠.
다음과 같이 입력하여 그 결과를 비교해 보세요.
- SELECT EMP_NUM
FROM EMP_SKILL
WHERE AVAILABLE IS NULL; - SELECT DISTINCT EMP_NUM
FROM EMP_SKILL
WHERE AVAILABLE IS NULL;
뭐가 다른지 모르겠다구요. 결과를 유심히 보세요. 차이를 발견해야지 다음 실습을 할 수 있습니다. - SELECT EMP_NUM
- 그럼 이번에는 다음과 같이 입력해서 바로 위 결과와 비교해 보세요.
- SELECT DISTINCT EMP_NUM, SKILL_NO
FROM EMP_SKILL
WHERE AVAILABLE IS NULL;
EMP_NUM과 SKILL_NO가 한꺼번에 중복된 것만 가려서 한번에 표시하고 EMP_NUM 또는 SKILL_NO 중 하나만 중복된 것은 중복을 허용하여 함께 표시합니다. - SELECT DISTINCT EMP_NUM, SKILL_NO
- distinct는 '별개의', '~와는 종류가 다른'이라는 뜻을 가진 단어입니다.
이번 시간에는 SQL의 컬럼 함수에 대해 알아보겠습니다. 여러 개의 컬럼 함수(Column Function) 중에서 자주 사용되는 다섯 가지 정도만 실습하도록 하겠습니다.
컬럼 함수는 대개 계산과 연관된 것으로 오라클과 같은 데이터베이스에서는 그 활용도가 다소 낮은 부분이라고 할 수 있습니다. 그러나 기본적으로 알고는 계셔야 합니다. 간혹 필요하니까요.
- Column Functions의 뜻과 특성을 먼저 알아봅시다.
- 컬럼 함수는 컬럼에 적용되는 함수입니다.
- 컬럼 함수를 적용하면 검색 결과로 하나의 Row(레코드)만 Return합니다.
이와는 다르게 다음 시간에 배울 스칼라 함수는 검색 결과로 여러 개의 레코드를 표시합니다. - 컬럼 함수를 적용하기 전에 WHERE 절의 조건에 만족한 ROW에 대해서만 함수가 적용됩니다.
- 만약 Column내에 NULL 값이 있다면 그 Row는 포함시키지 않습니다.
- 컬럼 함수는 컬럼에 적용되는 함수입니다.
- Column Function는 아래와 같은 것들이 있는데, 이름만 봐도 그 기능을 짐작할 수 있습니다. 개수를 구하는 COUNT, 평균을 구하는 AVG, 최대값은 MAX 등인데 그 결과로 당연히 하나의 결과만 나오겠죠. 평균이 여러 개이고 최대값이 여러 개일 수는 없으니까요.
- COUNT(a) a Column의 행의 수를 구합니다.
- AVG(a) a Column의 평균을 구합니다.
- SUM(a)) a Column의 합계를 구합니다.
- MIN(a)) a Column의 최소값을 구합니다.
- MAX(a)) a Column의 최대값을 구합니다.
- STDDEV(a)) a Column의 표준편차를 구합니다.
- VARIANCE(a)) a Column의 분산을 구합니다.
대표적인 몇 가지만 실습해 볼까요. - COUNT(a) a Column의 행의 수를 구합니다.
- 먼저 최소값을 구하는 MIN 함수입니다.
- MIN 함수는 검색 결과 값 중 가장 작은 값을 Return합니다.(즉 검색 결과 중 가장 작은 값을 찾아 보여 줍니다.)
- MIN 함수는 모든 Data 형에 사용할 수 있는데,
- 만약 컬럼의 데이터가 숫자형(numeric)이면 가장 작은 수를
- 문자형(character)이면 ASCII 코드 순으로 가장 작은 값을
- 날짜형(date)이면 현재로부터 가장 오래된 시간을 찾아 표시합니다.
- 만약 컬럼의 데이터가 숫자형(numeric)이면 가장 작은 수를
- NULL 값은 무시합니다.
- 실습해 봅시다. VIDEO 테이블에서 PLAY_TIME이 150 이상인 것 중에서 VIDEO_NO가 가장 작은 값을 구하려면..... 아래와 같이 하면 됩니다.
SELECT MIN(VIDEO_NO)
FROM VIDEO
WHERE PLAY_TIME >= 150;
SQL*Plus를 실행해 직접 실습해 보세요.(아래에서 설명하는 다른 함수들도 한번씩은 꼭 실습해 보세요.)
- MIN 함수는 검색 결과 값 중 가장 작은 값을 Return합니다.(즉 검색 결과 중 가장 작은 값을 찾아 보여 줍니다.)
- 최대값을 구하는 MAX 함수가 있는데, MIN 함수의 반대라고 생각하면 되죠.
실습은 생략하겠습니다. - 평균을 구하는 AVG 함수입니다.
- AVG 함수는 대상 Column의 평균값을 구해서 Return합니다.
- AVG함수는 숫자형(Numeric) 데이터를 가진 Column에만 사용할 수 있습니다.
- 만약 중복된 값이 있는 경우 중복된 값은 한번만 적용하게 하려면 앞서 다룬 Keyword인 Distinct를 사용하면 됩니다.
- AVG 함수도 NULL 값은 무시합니다.(즉 평균을 구할 때 NULL 값이 있는 데이터는 무시하고 구합니다.)
- VIDEO 테이블에서 PLAY_TIME의 평균을 구하려면...
SELECT AVG( PLAY_TIME )
FROM VIDEO; - PLAY_TIME 중에서 중복된 값은 한번만 적용하여 다시 평균을 구하려면...
SELECT AVG(DISTINCT PLAY_TIME )
FROM VIDEO;
- AVG 함수는 대상 Column의 평균값을 구해서 Return합니다.
- 합계를 구하는 SUM 함수에 대해 알아보죠.
- 대상 Column의 합계를 Return합니다.
- SUM 함수는 숫자형(Numeric) 데이터가 있는 Column에만 사용할 수 있습니다.
- AVG와 마찬가지로 중복된 값이 있는 경우 한번만 적용하게 하려면 Distinct 키워드를 사용하면 됩니다.
- SUM 함수도 NULL 값은 무시합니다.
- VIDEO 테이블에서 PLAY_TIME의 전체 합계를 구해보세요.
SELECT SUM( PLAY_TIME )
FROM VIDEO; - PLAY_TIME이 같은 값은 한번만 적용하여 전체 합계를 다시 구하려면...
SELECT SUM( DISTINCT PLAY_TIME )
FROM VIDEO;
- 대상 Column의 합계를 Return합니다.
- 마지막으로 행의 개수를 구하는 COUNT 함수입니다.
- COUNT 함수는 조건에 만족하는 모든 Row(레코드)의 개수를 Return합니다.
- 모든 데이터 형의 Column에 사용할 수 있습니다.
- COUNT(column_name)을 사용하면 특정 Column의 개수를 구하고
- COUNT(*)와 같이 사용하면 테이블 전체 Row(레코드)의 수를 구할 수 있습니다.
- 중복된 값이 있는 레코드를 한번만 적용하게 하려면 Distinct를 사용하여 중복된 레코드를 제외한 전체 레코드의 개수를 구할 수 있습니다.
- COUNT 함수도 NULL 값은 무시합니다.
- VIDEO 테이블의 전체 행(레코드)의 수를 구하려면...
SELECT COUNT( * )
FROM VIDEO; - VIDEO 테이블에서 PLAY_TIME에 값이 있는 행의 수를 구하되 PLAY_TIME이 같은 값이 여러 개일 경우 하나로 취급하여 개수를 구하려면...
SELECT COUNT( DISTINCT PLAY_TIME )
FROM VIDEO;
- COUNT 함수는 조건에 만족하는 모든 Row(레코드)의 개수를 Return합니다.
전체적으로 이해하기가 어렵지 않은 내용이었을 것입니다.
지난 시간에 컬럼 함수에 대해 알아봤습니다.
이번 시간에는 스칼라 함수에 대해 알아보겠습니다. Scalar란 수학에서 '실수로 표현할 수 있는 수량'이라는 뜻입니다.
스칼라 함수에는 크게 숫자형, 문자형, 날짜형, 변환형 함수 등으로 나눌 수 있습니다. 물론 이 분류가 정확한 것은 아니지만 여러 함수들 중에서 기능별로 비슷한 것끼리 묶어 보면 대략 이와 같음을 알 수 있습니다.
이번 시간에는 스칼라 함수 중에서 숫자형 함수에 대해서만 알아보도록 하겠습니다.
- 숫자형 함수의 종류
지난 시간의 컬럼 함수처럼 함수 이름만 봐도 그 기능을 이해할 수 있습니다.
ROUND 숫자를 반올림합니다.
TRUNC 숫자를 버림합니다.
MOD 어떤 수로 나누었을 때 나머지 구합니다.
CHR ASCII 값에 해당하는 문자를 구합니다.
POWER 거듭제곱을 구합니다.
SQRT 제곱근을 구합니다.
SIGN 양수인지 음수인지 0인지를 구별합니다. - ROUND와 TRUNC 함수
- 형식
ROUND(숫자값, 자릿수)
TRUNC(숫자값, 자릿수) - 소수점 이하 유효 자릿수까지 반올림하거나 버립니다.
- 자릿수의 수가 양수이면 소수 자리 이하, 음수이면 정수 부분 자리를 의미합니다. 아래 예를 보세요.
- SELECT ROUND (35.125, 2)
FROM DUAL;
35.125를 소숫점 이하 두자리까지 보이도록 반올림하라는 뜻입니다. 즉 소숫점 이하 세번째 자리에서 반올림해야 두번째자리까지 보이겠죠.
결과는 35.13이 됩니다.
여기서 DUAL이라는 테이블은 뭘까요?
지금까지 실습한 적이 없으니까 새로 만들까요? 아닙니다.
DUAL은 가상의 테이블입니다. 한 행 한 열로 이루어지 가상의 테이블입니다. 왠 가상의 테이블? 가상 테이블은 특별히 테이블이 필요없는 문장에서 어쩔 수 없이 형식적으로 붙여주는 겁니다.
위에서 보듯이 35.125를 소수점 이하 두자리까지 구하라는 것인데, 이를 위해 특별히 다른 테이블을 참조할 필요가 없습니다. 이럴 때 그냥 문법적으로 FROM 뒤에 테이블 이름이 와야하니까 DUAL이라는 형식적인 테이블 이름을 쓴 겁니다. 제가 만든 게 아니라 오라클에서 기본 제공되는 것입니다. - SELECT ROUND (35.125, -1)
FROM DUAL;
직접 실행해 볼까요?
35.125를 정수 일의 자리에서 반올림하라는 것입니다. 따라서 결과는 40이 됩니다.
만약 ROUND (35.125, 0)이라고 하면 결과는 35가 됩니다.
또 만약 ROUND(1357.123, -2)라고 하면 결과는 1400이 됩니다.
아래의 함수들도 한번씩 실행해 보세요. - SELECT TRUNC (35.125, 1)
FROM DUAL;
35.125를 소수점 이하 첫째자리까지 보이도록 버리라는 뜻입니다. 따라서 결과는 35.1이 됩니다.
- 형식
- MOD 함수
- 형식
MOD(숫자값, n) - 숫자값을 n으로 나눈 나머지를 구합니다.
- 다음 예만 보면 쉽게 이해가 될 겁니다.
SELECT MOD (100, 12)
FROM DUAL;
100을 12로 나눈 나머지를 구하라는 거죠... 으하하 계산이 안되죠? 계산기를 두들기든지 아니면 연습장에서 계산을 해보세요.
몫이 8이고 나머지가 4가 됩니다. 그러니까 결과는? 바로 4입니다.
- 형식
- POWER 함수
- 영어로 POWER는 수학에서 거듭 제곱이라는 의미입니다. 따라서 거듭 제곱을 구하는 함수입니다.
- SELECT POWER(10,3)
FROM DUAL;
10의 3제곱은 1000입니다. 설마 이거 이해 안되는 분 없죠? ^^
- 영어로 POWER는 수학에서 거듭 제곱이라는 의미입니다. 따라서 거듭 제곱을 구하는 함수입니다.
- SQRT 함수
- Square Root라는 뜻입니다. 풀이하자면 제곱 뿌리(?). 제곱근입니다.
- SELECT SQRT (25)
FROM DUAL;
루트 25는? 5입니다.
- Square Root라는 뜻입니다. 풀이하자면 제곱 뿌리(?). 제곱근입니다.
- SIGN 함수
- 양수이면 1, 음수이면 -1, 0이면 0의 값을 반환합니다.
- SELECT SIGN (10),
SIGN(-100),
SIGN(0)
FROM DUAL;
결과가 어떻게 될까요? 궁금하면 직접 실행해 보시든가 아니면 오른쪽 괄호 사이를 마우스로 드래그해보세요. 답이 보입니다. (1, -1, 0)
- 양수이면 1, 음수이면 -1, 0이면 0의 값을 반환합니다.
- CHR 함수
- 주어진 숫자의 ASCII CODE 값을 구합니다.
- SELECT CHR (65)
FROM DUAL;
아스키 코드값 65는 영문 대문자 'A'에 해당됩니다. 따라서 결과는 'A'가 되죠.
아스키 코드는 텍스트 파일을 위한 가장 일반적인 형식입니다. American Standard Code for Information Interchange의 약자입니다. 미국의 표준 코드이니 당연히 전세계 표준이 되겠죠. 기분은 나쁘지만...
아스키 코드를 전체적으로 다 보고 싶으시면 여기를 클릭하세요.
- 주어진 숫자의 ASCII CODE 값을 구합니다.
그렇게 어렵지 않죠? 오라클 기초 과정이어서 이 수준을 크게 넘어서지 않을 것입니다.
지난 시간을 통해 느끼셨듯이 Scalar 함수는 그리 어렵지 않습니다.
함수 이름만으로도 그 뜻이 짐작이 되고 사용법도 그리 복잡하지 않습니다.
오늘은 지난 시간에 이어 문자형 함수에 대해 그 종류를 간략하게 알아보고 간단한 실습을 해보도록 하겠습니다.
- 문자형 함수의 종류
- UPPER, LOWER, INITCAP 함수
백문이 불여일타, 일단 입력해 보고 그 결과를 봅시다.
SQL*Plus를 실행해서 다음 문장을 직접 입력해 보세요.
SELECT EMP_NUM,
LOWER(LAST_NAME),
INITCAP(FIRST_NAME),
UPPER(ADDRESS)
FROM EMP; - CONCAT 함수
문자열 합성 함수라고 했죠?
직접 한번 해보세요.
SELECT CONCAT( LAST_NAME, FIRST_NAME )
FROM EMP;
성과 이름이 모두 붙어서 출력됩니다.
그럼 이렇게 해보면 어떨까요?
SELECT CONCAT(FIRST_NAME, '님' )
FROM EMP;
직접 그 결과를 확인해 보세요. - SUBSTR 함수
이건 조금 설명 드려야겠네요.
일단
SUBSTR(arg1, start_position, length)와 같은 형식으로 쓰입니다.
여기서 arg1에는 컬럼 이름이 옵니다.
start_position이 양수이면 왼쪽부터 시작, 음수이면 오른쪽부터 시작하여 length 크기만큼 문자열을 자릅니다. 만약 length를 생략하면 나머지 start_position에서 시작하여 나머지 모두를 자릅니다.
그럼 아래 문장을 직접 입력해서 그 결과를 살펴 보세요.
SELECT SUBSTR( LAST_NAME, 2, 3 )
FROM EMP;
이렇게 하면 또 어떨까요?
SELECT SUBSTR( FIRST_NAME, -3)
FROM EMP;
그냥 FIRST_NAME을 SELECT했을 때와 비교해 보세요. - LENGTH 함수
특정 컬럼의 길이를 구하기 위한 함수인데, 한글과 영문 모두 1바이트로 취급합니다.
데이터의 유형별로 LENGTH 함수를 적용했을 때 구할 수 있는 길이가 조금 다른데,
NUMBER형 데이터라면 실제 길이를 구하고
DATE형 데이터라면 Default Date Format의 길이를 구합니다.
CHAR형이라면 정의된 길이를 구하고
VARCHAR2형이라면 정의된 길이와 상관없이 실제 길이를 구합니다.
LONG 형도 실제 길이를 구합니다.
자, 실습해 볼까요?
SELECT LENGTH(EMP_NUM),
LENGTH(ADDRESS)
FROM EMP; - LPAD/RPAD 함수
문자열의 왼쪽과 오른쪽의 공백을 특정 지정한 문자열로 채우는데 다음과 같이 사용합니다.
LPAD( arg1, length, arg2 )
RPAD( arg1, length, arg2 )
이때 arg1은 Column Name이나 문자열이어야 하고,
length는 전체 자릿수를 나타냅니다.
채우고자 하는 문자는 arg2 자리에 씁니다. 만약 생갹하면 공백으로 채워집니다.
아래와 같이 입력하면 어떤 결과가 나올까요?
SELECT LPAD( PLAY_TIME, 5, '*' ),
RPAD(PLAY_TIME, 5, '*' )
FROM VIDEO;
요건 직접 한번 해보세요. - LTRIM/RTRIM 함수
일단 형식부터 봅시다.
LTRIM( arg1, arg2 )
RTRIM( arg1, arg2 )
arg1의 문자열에서 더 이상 arg2의 문자열을 만나지 않을 때까지 지운 결과를 구합니다.
이때 arg1은 Column Name이나 문자열이고, arg2도 문자열입니다.
아래와 같이 입력해 보세요.
SELECT LTRIM( 'XXAXBA', 'X' ),
RTRIM('XXAXBA' , 'A' )
FROM DUAL;
결과가 예측됩니까?
LTRIM의 결과는 AXBA, RTRIM의 결과는 XXAXB가 되겠죠? - TRANSLATE/REPLACE
a 문자를 b문자로 바꾸고 싶다면,
TRANSLATE(arg, a, b)
과 같이 쓰면 됩니다.
이때 arg1은 Column Name이나 문자열이어야 합니다.
예를 들어,
SELECT TRANSLATE ('AABBA', 'B', 'C')
FROM DUAL;
라고 쓰면
결과는 AACCA가 되겠죠.
REPLACE를 사용하면 한 문자가 아니라 문자열로 교체할 수 있습니다.
예를 들어,
SELECT REPLACE ('JACK and JUE', 'J', 'BL')
FROM DUAL;
라고 쓰면
결과는 BLACK and BLUE가 되겠죠.
어려운 것은 없었을 것입니다.
앞으로 10여회의 강좌만 더하면 기초 과정이 끝납니다.
스칼라 함수 마지막 시간입니다. 날짜형, 변환형 그리고 기타 몇 가지 함수에 대해 살펴보겠습니다.
- 날짜형 함수의 종류
- SYSDATE
시스템의 현재 날짜를 구해 돌려주는데, 우리가 지금 실습하고 있는 Personal Oracle의 의 기본 유형은 YY/MM/DD입니다. 즉 01/03/27과 같은 식으로 구합니다.
아래와 같이 직접 입력해 보세요.
SELECT SYSDATE
FROM DUAL; - LAST_DAY(날짜)
주어진 날짜에 해당하는 월의 마지막 날짜를 구합니다.
SELECT LAST_DAY(SYSDATE)
FROM DUAL; - MONTHS_BETWEEN(날짜1, 날짜2)
날짜1과 날짜2의 달의 차이를 나타냅니다.
만약 날짜를 직접 입력할 때는 문자처럼 좌우를 작은 따옴표(' ')로 둘러싸야 합니다.
SELECT MONTHS_BETWEEN('02/03/27', '02/03/01')
FROM DUAL;
위와 같이 하면 결과가 .838709677이 됩니다.
이것은 3월 27일과 3월 1일의 차이는 약 0.838709677개월이라는 뜻입니다.
ADD_MONTHS(날짜, 숫자값)
주어진 날짜에 숫자만큼의 개월 수를 더한 결과를 구합니다.
예를 들어
SELECT ADD_MONTHS(SYSDATE, 12)
FROM DUAL; 라고 했을 때,
만약 오늘이 2002년 3월 27일이라면 12개월 후인 2003년 3월 27일이 표시되겠죠. 기본 포맷이 YY/MM/DD이니까 03/03/27이라고 표시되겠죠. - 변환형 함수의 종류
변환형 함수는 숫자형, 문자형, 날짜형 데이터를 서로 다른 형식으로 바꾸기 위해 사용합니다. - TO_CHAR(문자값, 형식)
숫자를 문자로 변환하거나 날짜를 문자로 변환할 때 사용하는 함수입니다.
문자값에는 숫자나 날짜 또는 컬럼 이름 등이 올 수 있습니다.
숫자를 정해진 형식의 문자로 바꿀 때 사용하는 기호들입니다.
무슨 말인지 잘 모르시겠죠? 다음과 같이 직접 입력해 보세요.
SELECT TO_CHAR(123456.789, 'L999,999.9')
FROM DUAL;
₩123,456.8와 같이 표시되면 정상입니다.
날짜를 정해진 형식의 문자로 바꿀 때 사용하는 기호들입니다.
- 날짜를 문자로 변환할 때는 대소문자를 구별해야 하니까 이 점 주의하시고,
- 만약 앞에 0이나 공백을 없애려면 'fm'을 사용합니다.
- 형식 내의 또 다른 문자를 포함하는 경우 (/ . , : 제외) 큰 따옴표(" ")를 사용해야 합니다.
다음과 같이 실행하면 어떻게 될까요?
SELECT TO_CHAR(SYSDATE, 'fmDD "of" Month YYYY HH24:MI')
FROM DUAL;
지금 실행하니까 이렇게 나오네요.
27 of March 2002 23:41 - 날짜를 문자로 변환할 때는 대소문자를 구별해야 하니까 이 점 주의하시고,
- TO_DATE(문자값, 형식 )
기본 날짜 형식(YY/MM/DD)이 아닌 다른 형식의 날짜를 날짜형으로 변환할 때 사용한다.
주로 DATE Type의 Column에 값을 입력할 때 많이 사용합니다. (Default Format이 아닐 경우에 사용)
다음을 보세요.
SELECT MONTHS_BETWEEN('02/03/01',
TO_DATE('JAN-01-02', 'MON-DD-YY'))
FROM DUAL;
2002년 3월 1일과 2002년 1월 1일의 차이를 구하는 것입니다. 결과는 2가 나올 것입니다. (두 달 차이가 나니까요.) - TO_NUMBER(문자값)
문자값을 숫자로 바꾸는 것입니다.
SELECT TO_NUMBER('1234')
FROM DUAL;
문자 1234가 아닌 숫자 1234로 바뀌겠죠.
그 외에 다음과 같은 함수들이 있습니다. - NVL(Column Name, '대체문자열')
Null을 허용하는 컬럼을 표시할 때 Null인 경우에는 원하는 값으로 바꾸어 표시합니다.
Null값을 대신할 대체 문자열이 반드시 있어야 합니다.
SELECT EMP_NUM,
NVL(AVAILABLE, 'NO')
FROM EMP_SKILL;
AVAILABLE 컬럼의 값이 Null 값일 경우 'NO'로 대체하여 표시합니다. - DECODE(컬럼이름, 원래값1, 대체값1, 원래값2, 대체값2, ... 기본대체값)
C 언어나 지금 한창 강좌 진행중인 PHP와 같은 언어에서 다음과 같은 역할을 합니다.
switch (컬럼값 )
{
case 원래값1: 대체값1;
case 원래값2: 대체값2;
...
기본대체값
}
잘 이해가 안 되시는 분 계실테니 예를 들어 설명드리죠.
SELECT EMP_NUM,
DECODE(SKILL_NO, 'S101', 'SCJP', 'S102', 'SCJD', 'OCP')
FROM EMP_SKILL;
위와 같이 하면
SKIL_NO 컬럼의 값이 'S101'이면 'SCJP'로 바꾸고, 'S102'면 'SCJD'로 바꾸고, 그렇지 않으면 모두 'OCP'로 바꾸어 표시하라는 뜻입니다.
오늘은 양이 좀 많았네요.
이번 시간에는 데이터 검색에 사용되는 ORDER BY와 GROUP BY 문에 대해 알아보기로 하겠습니다.
ORDER BY와 GROUP BY는 SELECT 문의 말미에 사용되며 검색된 결과를 다시 정렬하거나 그룹으로 묶어서 보여주는 기능을 합니다.
- OREDER BY
SELECT 문으로 검색한 결과를 특정한 컬럼을 기준으로 정렬하여 보여주고자 할 때 사용합니다.
다음과 같은 형식으로 사용합니다.
SELECT 컬럼1, 컬럼2, ...
INTO :변수1, :변수2, ...
FROM 테이블1, 테이블2, ...
WHERE 조건
ORDER BY column1 [asc], column2 desc, column3 ...
여기서 ORDER BY 뒤에 나열한 컬럼 순서대로 정렬됩니다. 즉 column1을 기준으로 먼저 정렬하고 column1의 값이 같을 경우 column2를 기준으로 정렬한다는 뜻입니다.
컬럼 이름 뒤의 asc 또는 desc는 오름차순, 내림차순을 의미합니다. 생략하면 기본적으로 오름차순으로 정렬됩니다.
자 다음과 같이 입력하고 그 결과를 확인해 보세요.
SELECT LAST_NAME, FIRST_NAME
FROM EMP
ORDER BY LAST_NAME, FIRST_NAME;
위에서 ORDER BY LAST_NAME, FIRST_NAME; 대신
ORDER BY 1, 2;와 같이 써도 됩니다. SELECT 문에서 사용한 컬럼 이름 순서대로 1, 2, 3...과 같이 부여해서 컬럼 이름 대신 숫자로 표시해도 된다는 뜻입니다. - GROUP BY
SELECT 문으로 검색한 결과를 특정 컬럼을 기준으로 그룹화하여 표시합니다.
여기서 그룹화라는 것은 특정 컬럼의 값이 같을 경우 해당 레코드를 모두 묶어서 하나로 표시한다는 뜻입니다.
먼저 GROUP BY를 사용할 때의 문장 형식은 다음과 같습니다.
SELECT 컬럼1, 컬럼2, 컬럼 함수 ...
INTO :변수1, :변수2, ...
FROM 테이블1, 테이블2, ...
WHERE 조건
GROUP BY 컬럼1, 컬럼2, ...
HAVING 조건
ORDER BY 컬럼1, 컬럼2,
위에서 보는 것과 같이 GROUP BY는 ORDER BY 위에서 사용해야 합니다.
그리고 HAVING 절을 사용할 수 있는데, 뒤에서 다루겠지만 HAVING은 GROUP을 만드는 조건을 나타냅니다.
백문이 불여일견. 일단 봅시다.
먼저 실습을 위해 다음과 DEPT_SALES라는 테이블을 하나 만들어야겠네요.
위에서 보면 DEPT_NO가 중복되는 레코드가 있죠?
그래서 지금 실습할 내용은 DEPT_NO가 중복되는 것끼리 묶어서(그룹화하여) AMOUNT의 평균을 구하는 것입니다. 즉 DEPT_NO가 201인 것의 AMOUNT 평균, 280의 평균, 501의 평균을 구하는 것이 목적입니다.
그러기 위해서 먼저 테이블을 만들어야겠죠.
아래의 코드를 복사하여 그대로 사용하시면 됩니다.
DROP TABLE DEPT_SALES;
CREATE TABLE DEPT_SALES
( DEPT_NO CHAR(3),
MONTH CHAR(2) NOT NULL,
AMOUNT NUMBER NOT NULL,
PLACE VARCHAR2(20),
PERSONNEL CHAR(2),
CONSTRAINT PK_DEPTNO_MONTH PRIMARY KEY(DEPT_NO, MONTH)
);
INSERT INTO DEPT_SALES VALUES ('201', '1', 450, 'SEOUL', '14');
INSERT INTO DEPT_SALES VALUES ('201', '2', 500, 'PUSAN', '16');
INSERT INTO DEPT_SALES VALUES ('280', '4', 300, 'SEOUL', '25');
INSERT INTO DEPT_SALES VALUES ('501', '4', 100, 'SEOUL', '14');
INSERT INTO DEPT_SALES VALUES ('501', '5', 150, 'SEOUL', '27');
INSERT INTO DEPT_SALES VALUES ('501', '6', 150, 'KWANGJU', '16');
이제 위에서 얻고자 하는 결과를 구하기 위해 다음과 같이 쿼리문을 작성합니다.
SELECT DEPT_NO, AVG(AMOUNT)
FROM DEPT_SALES
WHERE AMOUNT > 100
GROUP BY DEPT_NO;
위의 문장을 이해하셨다면, 문제 하나 내겠습니다.
지역(PLACE)별로 그룹화하여 지역별 AMOUNT의 평균을 구해보세요. 단, 지역명의 역순으로 정렬하세요.
해답을 보시려면 아래 빈곳을 마우스로 드래그해보세요.
SELECT PLACE, AVG(AMOUNT)
FROM DEPT_SALES
GROUP BY PLACE
ORDER BY PLACE DESC;
- HAVING 절
HAVING 절은 반드시 GROUP 절과 함께 사용됩니다.
SELECT 문의 일반적인 조건이 WHERE 절에서 표시한다면, GROUP 절에 대한 조건은 HAVING 절에 씁니다.
예를 들어,
SELECT DEPT_NO, AVG(AMOUNT)
FROM DEPT_SALES
WHERE AMOUNT > 100
GROUP BY DEPT_NO
HAVING AVG(AMOUNT) > 200;
위의 문장은 AMOUNT가 100을 초과하는 것 중에서 DEPT_NO를 기준으로 그룹화하되, 그룹화한 AMOUNT의 평균이 200을 초과하는 것만 표시하라는 뜻입니다.
이번 시간에는 딱 두가지 - ORDER BY와 GROUP BY에 대해 알아보았습니다. 그리고 GROUP BY는 별도의 조건절인 HAVING 절을 사용할 수 있다는 것도 알았습니다.
다음 시간에는 여러 테이블을 대상으로 데이터를 검색하기 위해 JOIN과 UNION 명령에 대해 알아 보겠습니다.
벌써 목요일 새벽입니다.
대개 한주의 피로를 가장 많이 느끼는 날이죠. 화이팅! 힘냅시다.
지금까지 우리는 하나의 테이블을 대상으로 검색 연습을 했습니다.
이번 시간에는 두 개 이상의 테이블로부터 원하는 데이터를 검색할 수 있는 방법에 대해 알아보기로 하죠.
두 개 이상의 테이블로부터 원하는 정보를 검색하기 위해서는 JOIN 문을 사용합니다.
그러나 JOIN이 반드시 두 개 이상의 테이블에서만 사용되는 것은 아닙니다. 하나의 테이블에서도 JOIN을 사용하여 마치 두 개의 테이블인 것처럼 사용할 수도 있습니다.(이것을 Self Join이라고 하는데 다음 시간에 다룹니다.)
JOIN 방법에는 EQUJOIN, NON-EQUJOIN, OUTER JOIN, SELF JOIN 등이 있는데
이번 시간에는 EQUJOIN에 대해서만 알아보기로 하겠습니다.
나머지 세 종류의 JOIN 방법은 다음 시간에 다루기로 하죠.
먼저 실습을 통해 EQUJOIN이 어떤 것인지 눈으로 확인부터 하죠.
아래와 같이 EMP_SKILL 테이블과 SKILL 테이블이 있다고 할 때,
EMP_NUM, SKILL_NO, SKILL_NAME을 한번에 표시하고 싶습니다.
그런데 EMP_NUM 컬럼은 EMP_SKILL 테이블에만 있고,
EMP_NO 컬럼은 EMP_SKILL과 SKILL 테이블 모두에 있고,
SKILL_NAME 컬럼은 SKILL 테이블에만 있습니다.
즉 표시하고 싶은 컬럼이 두 개의 테이블에 나뉘어 있다는 것입니다.
이럴 때 두 개의 테이블에서 원하는 컬럼만 골라서 표시하려 한다면 JOIN을 사용합니다.
- 실습을 하기 전에 SKILL 테이블 하나를 만듭시다.
다음 코드를 그대로 복사하여 실행하면 위와 같은 SKILL 테이블이 만들어집니다.
DROP TABLE SKILL;
CREATE TABLE SKILL
( SKILL_NO CHAR(4) PRIMARY KEY,
SKILL_NAME VARCHAR2(30) NOT NULL);
INSERT INTO SKILL VALUES ('C101', 'CUSTOMER ENGINEER');
INSERT INTO SKILL VALUES ('D101', 'DATABASE ADMIN');
INSERT INTO SKILL VALUES ('E101', 'ERP ENGINEER');
INSERT INTO SKILL VALUES ('P101', 'PROGRAMMER');
INSERT INTO SKILL VALUES ('S101', 'SYSTEM PROGRAMMER');
INSERT INTO SKILL VALUES ('S102', 'SYSTEM ADMIN'); - 다음과 같이 입력하여 그 결과를 살펴 봅시다.
SELECT A.EMP_NUM,
A.SKILL_NO,
B.SKILL_NAME
FROM EMP_SKILL A,
SKILL B
WHERE A.SKILL_NO = B.SKILL_NO;
FROM 절을 유의해서 보세요.
EMP_SKILL 테이블을 A라고 하고, SKILL 테이블을 B라고 한다는 뜻입니다.
그럴 때, A의 EMP_NUM과 A의 SKILL_NO와 B의 SKILL_NAME을 표시하라는 뜻입니다.
그런데 모두 표시하라는 것은 아닙니다. WHERE 절을 보면 A의 SKILL_NO와 B의 SKILL_NO가 같은 것만 표시하라는 것이죠.
이해되시죠?
자, 그럼 정리합니다.
- JOIN은 하나 이상의 테이블에서 원하는 컬럼을 검색할 때 사용합니다.
- 단, JOIN은 FROM 절에서 명시한 테이블의 컬럼에만 한정합니다.
- 이때 컬럼 간의 값들이 서로 일치할 때만 사용하는 JOIN을 EQUJOIN이라고 합니다.(위에서 실습한 거!)
- 반드시 WHERE 절이 있어야겠죠. 위의 예에서는 'A와 B의 EMP_NO가 같은 레코드 중에서'라는 조건이 있습니다.
그런데 만약 WHERE 조건이 생략되면...? 뒤에 설명이 아오겠지만 Cartesian Product라는 것이 발생합니다.(뒤에서 다시 설명하겠습니다.) - WHERE 조건은 최소한 테이블 수에서 하나를 뺀 것만큼은 있어야 합니다. 그래야 Cartesian Product라는 게 발생하지 않습니다.
- 위의 예에서 EMP_SKILL 테이블을 A로, SKILL 테이블을 B로 표현했죠? 이럴 때 A와 B를 Correlation Name(연관된 이름)이라고 부릅니다.
EQUJOIN에 대해 실습을 하나 더 해보죠.
다음과 같은 테이블이 있을 때
A의 EMP_NUM과 C의 EMP_NUM이 같고, B의 SKILL_NO와 C의 SKILL_NO가 같은 레코드를 골라 EMP_NUM, LAST_NAME, SKILL_NO, SKILL_NAME을 표시하려면 어떻게해야 할까요?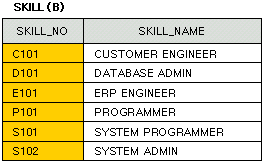
먼저 직접 해보시고, 답을 확인하시려면 아래의 빈 공간을 마우스로 드래그하면 보입니다.
SELECT A.EMP_NUM,
LAST_NAME,
B.SKILL_NO,
SKILL_NAME
FROM EMP A,
SKILL B,
EMP_SKILL C
WHERE C.EMP_NUM = A.EMP_NUM
AND C.SKILL_NO = B.SKILL_NO;
마지막으로 Cartesian Product(카티전 프로덕트)에 대해 짚고 넘어가겠습니다.
Cartesian은 원래 '데카르트의' 또는 '데카르트學'이라는 뜻입니다. 수학에서는 평행 또는 직각이라는 의미로 사용됩니다. Product는 수학에서 '곱'이라는 뜻이죠.
따라서 Cartesina Product는 '직각의 곱'(?)이라고 풀이하면...... 더 헤깔리겠죠?
수학에서 카티전 곱은 임의의 두 집합 A, B가 있을 때, A의 원소 a와 B의 원소 b를 조합하여 만든 (a,b)의 순서쌍을 모두 모은 집합을 뜻합니다. 따라서 A의 원소가 3개이고 B의 원소가 4개이면 A와 B의 Cartesian Porduct는 3×4개가 나옵니다.
아래 그림을 보시죠.
EMP_SKILL의 레코드가 7개, SKILL의 레코드가 6개가 되니까 두 테이블의 Cartesian Product는 42개의 레코드가 표시됩니다.
두 개의 테이블을 JOIN할 때 실수로 WHERE 절을 사용하지 않았거나 WHERE 조건을 잘못 지정하면 뜻하지 않게 이런 Cartesian Product가 발생하기도 합니다.
위의 그림을 보면 두 테이블의 SKILL_NO가 같은 레코드 중에서 EMP_NUM과 SKILL_NO, SKILL_NAME을 표시하면 7개의 레코드가 출력되어야 하는데,
잘못해서 WHERE A.SKILL_NO=B.SKILL_NO라는 조건을 주지 않으면 42개의 레코드가 출력됩니다.
생각보다 설명이 꽤 길어졌네요. 타이핑하느라 손가락이 다 아픕니다.
지난 시간에 JOIN 중에서도 EQUJOIN에 대해서만 알아봤습니다. 아울러 Cartisian Product의 개념에 대해서도 알아봤죠.
이번 시간에는 NON-EQUJOIN과 SELF JOIN에 대해 알아보겠습니다.
그리고 다음 시간에는 마지막으로 OUTER JOIN에 대해 다룰 예정입니다.
- NON-EQUJOIN
EQUJOIN이 아닌 것이 NON-EQUJOIN입니다.(썰렁~)
당연한 말이지만 지난 시간에 실습한 EQUJOIN에서 WHERE 조건식에 등호(=)가 사용되었습니다.
이를테면 아래와 같은 식이라는 거죠.
SELECT A.EMP_NUM, A.SKILL_NO, B.SKILL_NAME
FROM EMP_SKILL A, SKILL B
WHERE A.SKILL_NO = B.SKILL_NO;
위에서 A.SKILL_NO와 B.SKILL_NO가 같다는 조건식이 있습니다.
NON-EQUJOIN은 위와 같은 등호(=)를 이용한 조건식을 사용하지 않는 경우를 말합니다.
예를 들어 다음과 같이 BETWEEN을 사용하여 특정 범위를 지정할 수도 있습니다.
SELECT A.DEPTNO, A.DNAME, B.AMOUNT
FROM DEPT A, DEPT_SALES B
WHERE A.DEPTNO BETWEEN '100' AND '300'; - SELF JOIN
셀프 조인은 동일한 테이블에서 서로 다른 행을 연결하는 방법입니다. 두 개의 서로 다른 테이블을 JOIN하는 것과 같은 방식으로 합니다.
먼저 실습을 위해 다음 내용을 복사해서 실행합니다.(기존의 EMP 테이블을 비우고 새롭게 만든 다음 내용을 집어 넣는 명령들입니다.)
DROP TABLE EMP;
CREATE TABLE EMP (
EMP_NUM CHAR(5) PRIMARY KEY,
LAST_NAME VARCHAR2(30) NOT NULL,
FIRST_NAME VARCHAR2(30) NOT NULL,
JOB_CODE CHAR(2) NOT NULL,
ADDRESS VARCHAR2(100),
MGR_NUM CHAR(5) );
INSERT INTO EMP VALUES ( '10001', 'GRANT', 'LINDA', 'PE', '34 of 1st Street', NULL);
INSERT INTO EMP VALUES ( '10002', 'AMY', 'JONATHAN', 'PS', '200 Rose Street', '10001');
INSERT INTO EMP VALUES ( '10003', 'HUROW', 'LILY', 'SS', '101 Bear Town', '10001');
INSERT INTO EMP VALUES ( '10004', 'ADAM', 'EVELY', 'CS', '202 Declaration Drive', '10003');
INSERT INTO EMP VALUES ( '10005', 'JULIE', 'ROSE', 'PE', '788 McTyne Street', '10003');
INSERT INTO EMP VALUES ( '10006', 'ALBERT', 'MAY', 'SS', '320 Elaine Ave', '10003');
위의 EMP a와 EMP b는 동일한 테이블입니다.
EMP를 보세요. 둘째 줄을 보면 사원번호 10002인 AMY의 매니저번호는 10001입니다.
그런데 첫째 줄을 보면 사원번호 10001은 GRANT입니다.
즉 AMY의 매니저는 GRANT라는 뜻이죠.
마찬가지로 HUROW의 매니저도 GRANT, ADAM의 매니저는 HUROW가 됩니다.
여기서 다음과 같이 각각의 사원에 대한 매니저의 이름을 조회하려면 어떻게 해야할까요?
일단 아래 내용을 보기 전에 스스로 잠시 생각해 보시길...
SELECT A.EMP_NUM,
A.LAST_NAME "EMP_NAME",
A.MGR_NUM,
B.LAST_NAME "MANAGER_NAME"
FROM EMP A,
EMP B
WHERE A.MGR_NUM = B.EMP_NUM;
이렇게 하면 됩니다. 직접 실행해서 결과를 보세요.
WHERE 절을 보면 A.MGR_NUM과 B.EMP_NUM이 마치 다른 테이블의 컬럼처럼 보입니다. 그러나 FROM 절을 보면 아시다시피 하나의 EMP 테이블을 A와 B 두 가지로 명명했습니다.
위의 2행에서 A.LAST_NAME "EMP_NAME"이라고 쓴 것은 원래 컬럼 이름인 "LAST_NAME"을 실제 표시할 때는 "EMP_NAME"이라고 보여주라는 뜻입니다.(실제 컬럼 이름이 바뀌는 것이 아니라 SELECT 문으로 조회할 때만 바뀌어 보이는 것입니다.)
JOIN 마지막 시간입니다.
지난 시간의 EquJoin, NonEquJoin, SelfJoin에 이어 마지막으로 OuterJoin에 대해 알아보겠습니다.
Outer Join이란 Join조건을 만족하지 않는 경우에도 모든 행들을 다 보고자 할 경우에 사용하는 JOIN 방법입니다.
무슨 말이냐구요? 일단 다음 그림부터 봅시다.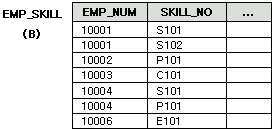
EMP 테이블의 EMP_NUM 컬럼과 EMP_SKILL 테이블의 EMP_NUM 컬럼을 보세요.
EMP_SKILL 테이블의 EMP_NUM 중에 10005와 10007이 없죠?
이럴 경우 다음과 같이 검색하면 어떤 결과가 나올까요?
SELECT A.EMP_NUM, LAST_NAME, B.SKILL_NO
FROM EMP A, EMP_SKILL B
WHERE A.EMP_NUM = B.EMP_NUM;
만약 위의 식을 정확하게 입력했다면 7개의 검색 결과가 나타날 것입니다.
EMP_NUM이 10001, 10001, 10002, 10003, 10004, 10004, 10006으로 나타날 것입니다. 중복된 것은 한번만 나타내라는 조건이 없으니까 B의 EMP_NUM을 기준으로 10001과 10004는 중복되어 나타나는 것입니다.
B의 EMP_NUM에 없는 10005와 10007은 검색되지 않을 것입니다.
그런데, 다음과 같이 검색식을 입력해 보세요.
SELECT A.EMP_NUM, LAST_NAME, B.SKILL_NO
FROM EMP A, EMP_SKILL B
WHERE A.EMP_NUM = B.EMP_NUM(+);
어떻습니까? 검색 결과가 9개가 나타납니다.
즉 B 테이블에 없던 10005와 10007도 표시됩니다. SKILL_NO가 Null인 상태로 말입니다.(B 테이블에 해당 SKILL_NO가 없으니까 Null로 표시된 것입니다.) 이때 SKILL_NO는 당연히 Null값이 허용되는 컬럼이겠죠.
그럼 이제 OuterJoin에 대해 정리하겠습니다.
- Outer Join이란 Join조건을 만족하지 않는 경우에도 모든 행들을 다 보고자 할 경우에 사용하는 JOIN 방법이다. 아까 위에서 말씀드렸죠?
- Outer Join을 하는 경우 (+)연산자를 사용한다.(괄호까지 포함합니다.)
- (+)를 사용하는 위치는 JOIN할 Data가 부족한 쪽에 위치시킨다.
- (+)는 WHERE절에서 비교연산자 기준으로 좌변 또는 우변의 어느 한쪽에만 위치시킨다. (양쪽 모두 사용할 수는 없습니다.)
- Outer Join에서 IN을 쓰거나 Outer Join 조건이 OR로 연결될 수 없다.
끝내기 전에 문제 하나 낼까요?
아래와 같이 (+)를 적용하면 어떤 결과가 나타날까요?
SELECT A.EMP_NUM, LAST_NAME, B.SKILL_NO
FROM EMP A, EMP_SKILL B
WHERE A.EMP_NUM(+) = B.EMP_NUM;
궁금하시면 직접 한번 해 보시길...
지난 시간까지 약 3회에 걸쳐 JOIN에 대해 다뤘습니다.
JOIN은 하나 이상의 테이블에서 특정한 컬럼을 검색할 때 사용했습니다.
이번 시간에 다룰 UNION도 하나 이상의 테이블에서 특정한 컬럼을 검색할 때 사용합니다.
JOIN 문은 WHERE 조건으로 두 개 이상의 테이블에서 원하는 컬럼을 선택하여 조회하지만, UNION은 두 개 이상의 SELECT 문을 사용하여 그 검색 결과를 합친다는 특징이 있습니다.
먼저 실습하기에 앞서 TEMPORARY라는 테이블이 필요합니다. 다음의 식을 복사하여 SQL*PLUS에 그대로 붙여 실행하시기 바랍니다.
DROP TABLE TEMPORARY;
CREATE TABLE TEMPORARY
( TEMP_NUM CHAR(5) PRIMARY KEY,
LAST_NAME VARCHAR2(30) NOT NULL,
FIRST_NAME VARCHAR2(30) NOT NULL,
PLACE VARCHAR2(30) );
INSERT INTO TEMPORARY VALUES ('20001', 'LISA', 'SMITH', 'SEOUL');
INSERT INTO TEMPORARY VALUES ('20002', 'KENNY', 'COLE', 'PUSAN');
INSERT INTO TEMPORARY VALUES ('10005', 'JULIE', 'ROSE', 'SEOUL');
자 그럼, 아래 그림을 보세요.
위와 같은 테이블에서, 다음 검색 식을 입력하면 어떻게 될까요?
SELECT LAST_NAME, FIRST_NAME
FROM EMP;
당연히 7개의 행이 검색되겠죠.
그럼 다음과 같이 입력하면?
SELECT LAST_NAME, FIRST_NAME
FROM TEMPORARY;
후후, 너무 쉽습니다. 당연히 3개의 행이 검색되겠죠.
그럼 위의 두 개의 식을 합쳐 볼까요?
이렇게 말입니다.
SELECT LAST_NAME, FIRST_NAME
FROM EMP
UNION
SELECT LAST_NAME, FIRST_NAME
FROM TEMPORARY
ORDER BY 1;
SELECT 문을 두 개 쓰고, 그 사이에 UNION으로 합쳐놓은 것입니다. 쉽죠?
그리고 마지막 줄에 ORDER BY 1은 첫 번째 컬럼으로 오름차순 정렬한다는 뜻입니다. 물론 ORDER BY 절을 반드시 써야하는 것은 아닙니다.
그럼 결과는 어떻게 나올까요?
7개 + 3개는 10개가 되겠지만, 9개가 나타납니다. EMP 테이블과 TEMPORARY 테이블에서 LAST_NAME과 FIRST_NAME이 같은 행이 하나 있죠? 바로 노란 색으로 표시된 JULIE ROSE 행이 중복되어서 하나만 표시되기 때문입니다.
만약 중복된 행이라도 모두 표시하고 싶다면 UNION 대신 UNION ALL을 쓰면 됩니다.
어려운 내용은 아니었을 겁니다.
내일이면 또 한 주가 시작되는 월요일입니다.
행복한 한 주 되시길 바랍니다.
어쩌다 보니 일요일마다 강좌를 올리게 되네요.
이번 시간부터 SUBSELECT에 관해 설명드리겠습니다.
SUBSELECT는 말 그대로 SELECT 문에 부속되는 SELECT문입니다. 통상 SELECT 문의 WHERE 절에 SELECT 문을 한번 더 쓰는 것을 말합니다. 즉 SELECT 문으로 검색한 결과를 이용해 어떤 조건식을 사용할 때 사용합니다.
역시 실제 예를 통해 설명하는 것이 낫겠네요. 그냥 개념을 설명하자니 말만 꼬이고...
SELECT EMP_NUM, LAST_NAME, FIRST_NAME, JOB_CODE
FROM EMP
WHERE EMP_NUM IN
(SELECT EMP_NUM
FROM EMP_SKILL
WHERE AVAILABLE = 'YES');
위에서 괄호로 묶은 부분이 SUBSELECT 문입니다. 괄호는 제가 임의로 붙인 것이 아니라 실제로 사용할 때에도 괄호를 사용해야 합니다. SUBSELECT 문은 반드시 괄호로 둘러싸야 합니다.
위의 문장의 실행 순서는 괄호로 묶인 파란 색 문장부터 실행됩니다.
- 즉, EMP_SKILL 테이블에서 AVAILABLE 컬럼의 값이 'YES'인 EMP_NUM 컬럼의 값을 먼저 검색합니다.
- 그런 다음, EMP 테이블에서 위의 검색 결과에 해당되는 EMP_NUM을 가진 행의 EMP_NUM, LAST_NAME, FIRST_NAME, JOB_CODE를 표시합니다.
이해가 잘 안되시면 다음과 같이 SUBSELECT 문을 떼어서 생각해 봅시다.
SELECT EMP_NUM
FROM EMP_SKILL
WHERE AVAILABLE = 'YES';
위의 결과는 10001과 10003입니다.
따라서 위의 결과를 토대로 EMP_NUM이 10001과 10003인 레코드의 EMP_NUM, LAST_NAME, FIRST_NAME, JOB_CODE를 표시하면...
IN 연산자에 대해서는 앞서 이미 설명 드렸죠?
주어진 조건을 만족하는 값이 하나라도 있으면 정상적으로 수행이 됩니다.(제22강 오라클 데이터 검색 - Keywords(1)에서 설명하고 있습니다.)
그럼, 이제 SUBSELECT에 대해 정리해 볼까요.
- SELECT의 WHERE절에 또 다른 SELECT를 기술한 것을 SUBSELECT라고 합니다.
- SUBSELECT의 결과 세트는 반드시 한 컬럼에 대한 값이어야 합니다.
- 일반적으로 바깥의 SELECT전에 SUBSELECT를 먼저 수행합니다.
- 반드시 SUBSELECT 문 전체를 괄호로 묶어야 합니다.
- SUBSELECT에서는 ORDER BY절을 사용할 수 없습니다.
지난 시간에는 IN 연산자를 사용하여 SUBSELECT 문의 용법을 알아 보았습니다.
이번 시간에는 SUBSELECT 문의 결과 세트를 비교 연산자를 이용해 재검색하는 방법을 알아 보겠습니다.
특히 비교 연산자를 ANY 또는 ALL 과 함께 사용했을 때 어떠한 결과가 나타나는지 주의깊게 보시기 바랍니다.
- 비교 연산자
아래는 일반적인 비교 연산자를 사용하는 예입니다.
전 시간의 내용을 이해하셨다면 별 어려움 없이 이해하실 수 있을 겁니다.
SELECT DEPT_NO, MONTH, AMOUNT
FROM DEPT_SALES
WHERE AMOUNT >
( SELECT AVG(AMOUNT)
FROM DEPT_SALES );
DEPT_SALES 테이블의 AMOUNT의 평균보다 큰 AMOUNT 값을 가진 레코드의 DEPT_NO, MONTH, AMOUNT를 표시하라는 뜻입니다.
DEPT_SALES 테이블의 AMOUNT 평균값이 275이니까 275보다 큰 AMOUNT 값을 가진 레코드만 표시되겠네요. - 비교 연산자와 ANY
SUBSELECT의 결과 세트 목록 중에서 최소한 하나라도 만족하는 것을 의미합니다.
경우에 따라서 최소값이 될 수도, 최대값이 될 수도 있습니다.
다음의 용례를 잘 살펴 보세요. 비교 연산자와 ANY가 함께 사용될 때 ANY가 최소값일 수도 최대값일 수도 있습니다.
ANY가 '어떠한'이라는 뜻이니까, 최소한 하나의 조건은 만족해야 합니다.
어떠한 값보다 크다는 것이 하나라도 만족하려면 '어떠한'이 '최소값'이 되어야겠죠.
반면 어떠한 값보다 작다는 것이 하나라도 만족하려면 '어떠한'이 '최대값'이 되어야 합니다.
- > ANY : 최소값 보다 크면
- >= ANY : 최소값보다 크거나 같으면
- < ANY : 최대값보다 작으면
- <= ANY : 최대값보다 작거나 같으면
- = ANY : IN과 같은 효과
- != ANY : NOT IN과 같은 효과
- > ANY : 최소값 보다 크면
- 비교 연산자와 ALL
ANY와는 반대되는 개념입니다.
- > ALL : 최대값 보다 크면
- >= ALL : 최대값보다 크거나 같으면
- < ALL : 최소값보다 작으면
- <= ALL : 최소값보다 작거나 같으면
- = ALL : SUBSELECT의 결과가 1건이면 상관없지만 여러 건이면 오류가 발생합니다.
- != ALL : 위와 마찬가지로 SUBSELECT의 결과가 여러 건이면 오류가 발생합니다.
- > ALL : 최대값 보다 크면
그럼 다음의 예제를 직접 실행해 보고 그 결과를 확인해 보세요.
SELECT EMP_NUM, LAST_NAME, FIRST_NAME, JOB_CODE
FROM EMP
WHERE EMP_NUM > ANY
( SELECT EMP_NUM
FROM EMP_SKILL
WHERE AVAILABLE = 'YES');
SELECT EMP_NUM, LAST_NAME, FIRST_NAME, JOB_CODE
FROM EMP
WHERE EMP_NUM > ALL
( SELECT EMP_NUM
FROM EMP_SKILL
WHERE AVAILABLE = 'YES');
SUBSELECT 마지막 시간입니다.
SUBSELECT의 결과 값이 하나라도 있으면 실행되는 EXIST에 관한 용례를 살펴보고,
SUBSELECT문을 FROM 절과 HAVING 절에서 사용할 때의 특징에 대해서도 알아보겠습니다.
- EXIST
WHERE 절에서 EXIST를 사용하면,
SUBSELECT 문의 결과가 True이면 SELECT 문을 수행하고 그렇지 않으면 수행하지 않습니다.
SELECT EMP_NUM, LAST_NAME, FIRST_NAME, JOB_CODE
FROM EMP
WHERE EXISTS
( SELECT *
FROM EMP_SKILL
WHERE AVAILABLE = 'YES');
EMP_SKILL 테이블에서 AVAILABLE의 값이 'YES'인 레코드가 존재하면, EMP 테이블의 EMP_NUM, LAST_NAME, FIRST_NAME, JOB_CODE를 표시하라는 뜻입니다. - FROM 절에서 SUBSELECT 사용하기
SUBSELECT 문은 WHERE 절 뿐만 아니라 FROM 절에서도 사용할 수 있습니다.
WHERE 절에서 사용하는 것과 결과는 동일하지만
TABLE에 데이터가 많을 때 사용하면 효과적입니다.
그 이유는, FROM 절에서 SUBSELECT는 VIEW와 같은 역할을 하기 때문입니다.(VIEW에 대해서는 몇 강좌 후에 다룰 예정입니다.)
SELECT EMP_NUM, SKILL_NAME
FROM ( SELECT EMP_NUM, SKILL_NAME, AVAILABLE
FROM SKILL A, EMP_SKILL B
WHERE A.SKILL_NO = B.SKILL_NO)
WHERE AVAILABLE = 'YES'; - HAVING 절에서 SUBSELECT 사용하기
앞서 배운 적이 있지요? HAVING 절은 GROUP을 만드는 조건을 지정할 때 사용합니다.(제28강 오라클 데이터 검색 - ORDER BY, GROUP BY를 보세요.)
사용법은 WHERE 절에서 사용할 때와 같습니다.
SELECT DEPT_NO, AVG(AMOUNT)
FROM DEPT_SALES
WHERE AMOUNT > 100
GROUP BY DEPT_NO
HAVING AVG(AMOUNT) >
( SELECT AVG(AMOUNT)
FROM DEPT_SALES);
일요일이 몇 시간 남지 않았네요.
지금까지 SELECT 문에 대해 장시간에 걸쳐 실습해 보았습니다.
이번 시간부터는 UPDATE, INSERT, DELETE 문에 대해 차례대로 알아 보겠습니다.
UPDATE, INSERT, DELETE 문을 보통 DML - Data Manipulation Language라고 합니다. 우리말로 데이터 조작어라고 번역할 수 있습니다.
SQL 명령어의 분류에 대해서는 이미 제19강 SQL과 SQL*Plus에서 다룬 적이 있습니다. 혹시 기억이 안나시면 참조하시기 바랍니다.
오늘은 DML, 그 첫시간으로 UPDATE 명령에 대해 알아 보겠습니다.
- UPDATE 형식과 특징
UPDATE table_name
SET column_one = expression, column_two = expression, …
WHERE search condition(s);
- UPDATE는 테이블의 행(레코드) 값을 ‘변경’할 때 사용합니다.
- 하나의 UPDATE 문으로 하나의 테이블 또는 뷰(View)만 수정할 수 있습니다.
예를 들어 하나의 뷰(View)라고 해도 여러 개의 테이블로부터 만들어진 뷰라면 UPDATE 문을 쓸 수 없습니다. - SET절에서 원하는 컬럼에 특정 값을 대입합니다. 이때 변경을 원하는 컬럼만 표시하면 됩니다.
- 테이블의 프라이머리 키는 UPDAGE할 수 없습니다.
단, 프라이머리 키라고 해도 다른 테이블에서 FK(외래키)로 참조하지 않으면 UPDATE할 수 있습니다. - WHERE에서 조건을 지정합니다.
만약 WHERE절이 없으면 테이블의 모든 행(레코드)를 UPDATE합니다.
- UPDATE는 테이블의 행(레코드) 값을 ‘변경’할 때 사용합니다.
- 실습을 위한 테이블 만들기
이번 시간 실습을 위해 다음과 같은 CLASS 테이블과 CUSTOMER 테이블을 만들어 둡시다.
테이블을 만들기 위한 명령어인 CREATE에 대해서는 다음 시간에 다룹니다. 드디어!
CREATE TABLE CLASS
( CODE CHAR(3) PRIMARY KEY,
DESCRIPTION VARCHAR2(30));
INSERT INTO CLASS VALUES ('F01', 'FIRST');
INSERT INTO CLASS VALUES ('B01', 'BUSINESS');
INSERT INTO CLASS VALUES ('E01', 'ECONOMY');
CREATE TABLE CUSTOMER
( CUST_NO CHAR(3) PRIMARY KEY,
NAME VARCHAR2(10) NOT NULL,
MILEAGE NUMBER,
CODE CHAR(3),
REG_DATE DATE NOT NULL);
INSERT INTO CUSTOMER VALUES ('100', '김철수', 10000, 'F01', '01/01/01');
INSERT INTO CUSTOMER VALUES ('101', '이윤정', 2000, 'E01', '01/03/05');
INSERT INTO CUSTOMER VALUES ('102', '박준서', 5000, 'B01', '01/02/28');
INSERT INTO CUSTOMER VALUES ('103', '김종현', 12000, 'F01', '01/08/15'); - 실습 1
다음과 같은 EMP 테이블에서 EMP_NUM이 10001인 레코드의 JOB_CODE를 “SS"로 변경해 봅시다.
UPDATE EMP
SET JOB_CODE = 'SS'
WHERE EMP_NUM = '10001'; - 실습 2
다음과 같은 CUSTOMER 테이블과 CLASS 테이블이 있다고 할 때,
DESCRIPTION이 “FIRST"인 CODE에 해당하는 사람의 마일리지를 50% 추가해 봅시다.
두 개의 테이블이 있고, 서로 참조해야 하기 때문에 SubSelect 문을 사용해야 되겠죠?
UPDATE CUSTOMER
SET MILEAGE = MILEAGE * 1.5
WHERE CODE = ( SELECT CODE
FROM CLASS
WHERE DESCRIPTION = 'FIRST');
비교적 쉬운 내용입니다.
실습 2에서 다시 나온 SubSelect 문은 실무에서 매우 유용하게 사용됩니다. 꼭 숙지하도록 해 주시기 바랍니다.
지난 시간에 UPDATE 문에 대해 알아보았습니다.
이번 시간에도 역시 DML의 하나인 INSERT 문에 대해 알아보기로 하겠습니다.
- INSERT문의 형식과 특징
INSERT INTO table_name (column_one, column_two, …)
VALUES (expression_one, expression_two,…);
- INTO 다음에 오는 테이블에 VALUE의 값을 삽입하는 역할을 합니다.
이때 INTO 절 다음에 기술하는 column명은 생략할 수 있습니다. - VALUES 절에는 상수(CONSTANT) 값, 널(NULL) 값, SYSDATE 등을 쓸 수 있습니다.
위와 같은 CUSTOMER 테이블에 노란 색 부분('104', '윤지수', 등록날짜)의 데이터를 삽입하려면 다음과 같이 씁니다.
INSERT INTO CUSTOMER ( CUST_NO, NAME, MILEAGE, CODE, REG_DATE)
VALUES ('104', '윤지수', NULL, NULL, SYSDATE);
여기서 주의할 것은 MILEAGE와 CODE에는 아무 값도 넣지 않았습니다. 이럴 때 NULL을 사용합니다.
그리고 REG_DATE에는 위의 데이터를 입력한 날짜를 집어넣기 위해 SYSDATE를 사용하였습니다. - INTO 다음에 오는 테이블에 VALUE의 값을 삽입하는 역할을 합니다.
- INSERT 문에서 SUBSELECT 사용
위의 예는 데이터를 직접 입력할 경우에 해당되는 것입니다.
만약 데이터를 입력받을 테이블이 있을 경우 이 테이블의 어떤 값을 다른 테이블로 입력할 경우에는 어떻게 할까요?
바로 VALUE 절에 SELECT 문을 이용하여 조건에 맞는 데이터를 골라 다른 테이블에 직접 입력할 수도 있습니다.
이 경우 두 테이블의 칼럼 형식은 같아야 되겠죠.
자, 그럼 아래 COSTOMER 테이블에서 마일리지(MILEAGE)가 10,000 이상인 고객 정보를 VIP 테이블에 입력하려면 어떻게 할까요?
↓
INSERT INTO VIP
SELECT *
FROM CUSTOMER
WHERE MILEAGE >= 10000;
여기서 주의해야할 것은,
- SUBSELECT 문의 WHERE 절을 생략하면 테이블의 모든 데이터가 백업됩니다.(일부러 데이터를 백업할 때 이런 식으로 사용합니다.)
- INSERT 문에서 SUBSELECT를 쓸 경우 VALUES와 ( )를 사용할 수 없습니다.
- SUBSELECT 문의 WHERE 절을 생략하면 테이블의 모든 데이터가 백업됩니다.(일부러 데이터를 백업할 때 이런 식으로 사용합니다.)
UPDATE, INSERT에 이어 이번 시간에는 행(레코드)을 삭제하는 명령인 DELETE 명령에 대해 알아보겠습니다.
- DELETE는 특정 행(레코드)를 삭제할 때 사용하며, DELETE 문의 형식은 다음과 같습니다.
DELETE FROM table_name
WHERE search condition(s); - 위의 문장을 보면 아시겠지만 DELETE 문에는 특정 컬럼 이름은 기술하지는 않습니다. 즉 행 전체가 아닌 하나의 행(레코드) 중에서 일부 컬럼만 삭제할 수는 없습니다.
- 위에서 WHERE 절을 생략하면 어떻게 될까요?
테이블의 모든 행이 삭제됩니다. - 그러나 DELETE 명령으로 데이터(행)만 삭제할 수 있지, 테이블 구조는 삭제할 수 없습니다. 테이블 자체를 삭제하려면 DELETE가 아닌 DROP 명령을 사용합니다.
다음과 같은 테이블이 있다고 가정해 봅시다.
그리고 노란색으로 표시된 10003, 10006, 10007번 레코드, 즉 JOB_CODE가 'SS'인 레코드를 삭제해 볼까요.
DELETE
FROM EMP
WHERE JOB_CODE = 'SS';
쉽죠?
그럼, 이번에는 조금 고차원(?)적인 문제 하나.
다음과 같은 EMP 테이블에서, EMP_SKILL 테이블의 EMP_NUM을 가지고 있지 않은 테이블을 모두 삭제하려면 어떻게 해야할까요?
이럴 땐, SUBSELECT 문을 써야겠죠.
직접 한번 생각해 보신 다음, 정답을 보시려면 아래 빈 칸을 마우스로 드래그해 보세요.
DELETE
FROM EMP
WHERE EMP_NUM NOT IN
(SELECT EMP_NUM
FROM EMP_SKILL );
이상 동주 아빠 손병목이었습니다.
데이터베이스에서 트랜잭션(Transaction)이란 논리적인 일의 단위를 말합니다. 개념적으로 설명하기에는 추상적이고 모호한 면이 많아 실례를 들어 설명하는 편이 훨씬 이해하기에 빠를 것입니다.
아래 그림을 보세요.
사용자가 INSERT 문을 사용해 데이터를 삽입하고, UPDATE 문으로 데이터를 갱신하고, DELETE 문으로 데이터를 삭제하였다고 합시다. 만약 이 모든 과정이 오류없이 수행되었다면 지금까지 실행한 모든 작업을 '실제로' 수행하라는 명령을 내릴 수 있는데 이 때의 명령이 바로 'COMMIT' 명령입니다. 'COMMIT' 명령을 주기 전까지의 모든 작업은 'ROLLBACK' 명령으로 원상태로 되돌릴 수 있는 것입니다.
만약 INSERT 작업을 한 다음 'SAVEPOINT A'라는 명령을 실행하였다면 나중에 'ROLLBACK A'라는 명령을 통해 INSERT 작업을 한 그 위치로 되돌아 올 수 있는 것이죠. 그 전에 'COMMIT' 명령을 실행하지 않았다면 말입니다.
이와 같이 COMMIT 명령으로 하나의 작업이 성공적으로 끝났을 때 우리는 트랜잭션이 성공적으로 수행되었다고 말합니다.
트랜잭션 제어를 위한 명령어(Transaction Coltrol Language)에는 다음과 같은 것들이 있습니다.
- COMMIT
- SAVEPOINT
- ROLLBACK
하나 하나 살펴볼까요?
- COMMIT은 저장되지 않은 모든 데이터를 데이터베이스에 저장하고 현재의 트랜잭션을 종료하라는 명령입니다.
- SAVEPOINT [이름]는 현재까지의 트랜잭션을 특정 이름으로 지정하라는 명령입니다.
- ROLLBACK [TO SAVEPOINT 이름]저장되지 않은 모든 데이터 변경 사항을 취소하고 현재의 트랜잭션을 끝내라는 명령입니다. 만약 이전에 SAVEPOINT로 지정한 이름이 있으면 그 위치까지 되돌아 갑니다.
이와 같이 COMMIT 또는 ROLLBACK 명령으로 직접 트랜잭션을 완성하거나 취소할 수도 있지만,
다음과 같은 경우에는 자동으로 트랜잭션이 종료됩니다.
- DDL(CREATE, ALTER, DROP) 명령어를 실행할 때
- DCL(GRANT, REVOKE) 명령어를 실행할 때
- Deadlock같은 특정 Error를 만날 때
- SQL*Plus를 종료할 때
위와 같은 경우에는 COMMIT나 ROLLBACK 문이 없어도 트랜잭션이 종료됩니다.
그럼, 정리하는 의미로 다음과 같이 작업을 할 경우 어떠한 결과가 나타날지 한번 생각해 보세요.
- SQL*Plus시작
- SELECT * FROM EMP;
- UPDATE EMP
SET JOB_CODE = 'AA'
WHERE EMP_NUM = '10001'; - SAVEPOINT update_point;
- DELETE FROM EMP;
- ROLLBACK TO update_point;
- DELETE FROM EMP
WHERE JOB_CODE = 'SS'; - COMMIT;
- INSERT INTO CUSTOMER
VALUES ('103', 손병목 , NULL, NULL, SYSDATE);
이번 시간부터는 데이터 정의어에 대해 알아보겠습니다.
데이터 정의어(DDL)는 테이블을 생성하는 CREATE, 테이블의 구조를 변경하는 ALTER, 테이블을 삭제하는 DROP 명령 등이 있습니다.
두 시간에 걸쳐 CREATE에 대해 살펴보겠습니다.
CREATE 명령은 구체적으로 설명한 적은 없지만 지금까지 꽤 많이 실습을 해왔습니다.
예제 테이블을 만들기 위해 CREATE 문을 사용했습니다. 다만 구체적으로 설명만 안했을 뿐이죠.
CREATE 문은 어떻게 구성되어 있는지 한번 살펴볼까요?
- CREATE 문 형식
CREATE TABLE table_name
(column_one data_type [constraint, DEFAULT expression],
column_two data_type [constraint, DEFAULT expression],
…,
CONSTRAINT constraint_name UNIQUE(column),
CONSTRAINT constraint_name PRIMARY KEY(column),
CONSTRAINT constraint_name FOREIGN KEY(column1)
REFERENCES table_name(column2),
CONSTRAINT constraint_name CHECK(column expr),
);
우선 눈에 띄는 것들이 몇 개 보이죠?
CONSTRAINT, UNIQUE, PRIMARY KEY, FOREIGN KEY, REFERENCES, CHECK 등
먼저 CONSTRAINT는 데이터의 무결성(Integrity)을 유지하기 위하여 사용자가 지정하는 제약 조건을 의미합니다.
무결성에 대해서는 이미 2, 3, 12, 14강에서 두루 언급되었던 내용이니 여기서는 따로 설명하지 않겠습니다.
CONSTRAINT를 정의하는 방법은 두 가지가 있습니다.
컬럼별로 제약 조건을 지정하는 것이 있고, Composite 컬럼에 대해 제약 조건을 정의할 수 있습니다.(Composite 컬럼에 대해서는 제13강에서 설명하였습니다.)
- 컬럼별로 제약 조건을 지정할 때는 어떠한 제약 조건도 사용 가능합니다.
- 그러나 Composite 컬럼에 대해서는 NOT NULL을 사용할 수 없습니다.
그럼, 구체적으로 제약 조건(CONSTRAINT)에는 어떤 것들이 있을까요?
이미 많이 보아온 것들이 그리 낯설지는 않을 것입니다. - 컬럼별로 제약 조건을 지정할 때는 어떠한 제약 조건도 사용 가능합니다.
- CONSTRAINT의 종류
이미 이 강좌 앞 부분에서 많이 언급된 것들이라 의미는 대부분 이해하셨을 거라 믿고 주요한 몇 가지만 짚고 넘어가겠습니다.
- NOT NULL
NOT NULL Constraint가 지정된 컬럼은 NULL 값을 가질 수 없습니다.
그리고 컬럼 단위로 Constraint를 지정할 때만 사용할 수 있습니다.(Composite 컬럼에는 사용할 수 없습니다.) - UNIQUE
예전에 ERD 설명하면서 언급한 적이 있죠? Unique는 말 그대로 중복되지 않아야 한다는 속성입니다.
단일 컬럼이나 Composite 컬럼에 Unique 속성을 부여할 때 사용하고, Unique로 지정되면 Unique Index가 자동으로 생성됩니다.(인덱스는 나중에 다룹니다.)
UNIQUE 컬럼에는 NULL 값이 반드시 없어야될 것 같지만, Composite 컬럼 중의 일부 컬럼에는 NULL 값이 들어갈 수 있는 경우도 있습니다. - PRIMARY KEY
테이블에서 PRIMARY KEY는 단 하나만 있어야 합니다.
그리고 당연히 NULL 값은 허용하지 않습니다.
UNIQUE로 지정했을 때와 마찬가지로 Unique Index가 자동으로 생성됩니다. - FOREIGN KEY
Primary Key, Foreign Key에 대해서는 제13강 관계형 데이터베이스(2)-Table Keys에서 자세히 다루고 있습니다.
자식 테이블(Child Table)에서 정의하는 Constraint이고, 부모 테이블(Parent Table)의 값과 일치하거나 NULL 값이어야 합니다.
FOREIGN KEY로 참조하고자 하는 테이블이 먼저 생성되어 있어야 합니다.
ON DELETE CASCADE Option을 주면 Cascade Delete RI를 적용할 수 있습니다.(Cascade Delete RI에 대한 설명은 제14강 관계형 데이터베이스(3)-참조무결성에서 자세히 설명하고 있습니다.) - CHECK
각 행의 컬럼이 만족해야 하는 구체적인 조건을 정의하는 곳입니다. - DEFAULT expression
테이블에 데이터를 입력할 때 특정 값을 지정하지 않은 경우 기본적으로 입력되는 값을 지정합니다. 예를 들어 현재의 날짜를 자동으로 삽입하려면 SYSDATE를 사용할 수 있겠죠.
- NOT NULL
이번 시간은 여기까지 설명하고,
계속해서 테이블을 직접 만들어 보기로 하겠습니다.
지난 시간에 이어 바로 실습으로 넘어갑니다.
아래와 같은 구조의 C_DEPT 테이블을 만들려고 합니다.
지난 시간에 다룬 CREATE 문의 형식을 참조해서 한번 만들어 봅시다.
샘플 데이터는 38강에서 다룬 INSERT 문을 참조해서 직접 해보시고, 이번 시간에는 CREATE 문만 함께 하기로 하죠.
아래 빈 곳을 마우스로 드래그하면 위와 같은 테이블을 만드는 CREATE 문이 있습니다. 먼저 곰곰이 생각해 보시고 확인해 보시기 바랍니다.
CREATE TABLE C_DEPT
( DEPT_NO NUMBER(2) PRIMARY KEY,
DEPT_NAME VARCHAR2(30) NOT NULL );
마찬가지로 아래와 같은 구조의 테이블을 만들려고 합니다.
잘 생각해 보시고 아래 빈곳을 드래그해서 확인하시기 바랍니다.
CREATE TABLE C_EMP
(EMP_NUM CHAR(5),
EMP_NAME VARCHAR2(30) NOT NULL,
HIRE_DATE DATE DEFAULT SYSDATE NOT NULL,
RETIRE_DATE DATE,
DEPT_NO NUMBER(2),
CONSTRAINT PK_EMPNUM PRIMARY KEY(EMP_NUM),
CONSTRAINT FK_DEPTNO FOREIGN KEY(DEPT_NO)
REFERENCES C_DEPT(DEPT_NO) );
위에서 실습한 두 가지 방법은 약간의 차이가 있습니다.
먼저 실습한 C_DEPT의 경우, 컬럼별로 CONSTRAINT를 지정하였습니다. 이럴 경우 별도로 CONSTRAINT 절을 명시하지 않아도 됩니다.
반면 C_EMP 테이블은 별도의 CONSTRAINT 절을 사용하여 CONSTRAINT를 지정하였습니다.
어느 것이 더 편한 방법인지는 사용자의 몫입니다.
지난 시간에 CREATE를 이용해 테이블을 만드는 DDL을 실습했습니다.
이번 시간에는 만들어 놓은 테이블을 변경하는 명령인 ALTER에 대해 실습하겠습니다.(그리고 다음 시간에는 삭제 명령인 DROP을 실습할 예정입니다.)
- ALTER는,
- 기존 테이블에 새로운 컬럼을 추가하거나 변경(컬럼의 데이터형 변경 등)할 때 ALTER 명령을 사용합니다.
- ALTER 명령은 Constraint를 추가하거나 삭제할 때도 사용할 수 있습니다.
- 그러나 CREATE TABLE 문으로 만든 컬럼은 삭제할 수 없습니다.
- 기존 테이블에 새로운 컬럼을 추가하거나 변경(컬럼의 데이터형 변경 등)할 때 ALTER 명령을 사용합니다.
- ALTER 문은 다음과 같이 사용됩니다.
ALTER TABLE table_name
ADD ( column_name datatype )
MODIFY( column_name datatype )
ADD CONSTRAINT constraint_name expr
DROP CONSTRAINT constraint_name; - 실습 1
기존 C_EMP 테이블에 AGE 컬럼을 추가하고 기존의 EMP_NAME 컬럼의 길이를 20으로 줄이기.(단, AGE는 0보다 커야하고, 이 조건의 이름을 CK_AGE라고 한다.)
ALTER TABLE C_EMP
ADD (AGE NUMBER(3))
MODIFY (EMP_NAME VARCHAR(20))
ADD CONSTRAINT CK_AGE CHECK(AGE > 0); - 실습 2
C_EMP 테이블에서 기존의 FK_DEPTNO라는 CONSTRAINT를 삭제하기
ALTER TABLE C_EMP
DROP CONSTRAINT FK_DEPTNO; - 실습 3
C_EMP 테이블에서 DEPT_NO 컬럼에 Foreign Key Constraint를 추가하기(단, Foreign Key Constraint의 이름은 FK_EMP_DEPTNO로 한다.)
ALTER TABLE C_EMP
ADD CONSTRAINT FK_EMP_DEPTNO
FOREIGN KEY(DEPT_NO) REFERENCES DEPT;
문법적으로 어려운 것은 전혀 없는데 실제 실무에서 사용하려고 하면 잘 기억나지 않을 때가 있습니다.
모든 것이 그러하듯 자주 사용해야 기억할 수 있겠죠.
테이블을 만들고 변경하는 실습을 해 보았습니다.
이번 시간에는 테이블을 삭제하는 연습을 해보겠습니다.
테이블을 삭제하는 것은 테이블을 생성하거나 변경하는 것에 비해 정말 간단합니다.
테이블을 삭제할 때는 DROP 명령을 사용합니다.
DROP TABLE 테이블명;
정말 간단하죠?
만약 TEST 테이블을 삭제하려면?
DROP TABLE TEST;
라고만 하면 됩니다.
39강에서 DELETE 명령을 배운 적이 있습니다. DELETE가 테이블의 ‘데이터’를 삭제하는 것이라면, DROP 명령은 테이블 자체를 삭제해 버립니다. 즉 테이블의 데이터를 포함한 구조(Structure)를 삭제합니다.
이 외에도 DELETE 명령은 실수했을 경우 되돌릴 수 있는 반면, DROP 명령은 되돌릴 수 없습니다.(참고로 DELETE 명령은 SQL DML 명령이고, DROP은 SQL DDL 명령입니다.)
40강에서 트랜잭션을 설명할 때 DDL 명령을 실행하면 자동으로 COMMIT 명령을 준 것과 동일한 결과가 나타난다고 했었죠. 바로 DROP 명령도 DDL 명령의 일종이기 때문에 DROP 명령을 내리는 순간 트랜잭션의 완료를 의미하는 COMMIT 명령이 동시에 실행되는 것입니다. 그러니, 조심 또 조심해서 DROP 명령을 사용하라는 뜻입니다.
만약 이것이 불안하다면 미리 백업을 해두면 되죠.(그러나 아쉽게도 본 강의는 백업과 복구 관련 내용까지는 설명하지 않습니다. 다음에 기회가 되면 중급 과정을 하나 더 만들어 설명하기로 하죠...)
오늘은 정말 간단합니다. 이상 DROP 설명은 끝~
드디어 DB(오라클 SQL) 입문 강좌 마지막 시간입니다.
'입문'의 범위가 어디까지인지는 어디까지나 주관적인 판단에 의한 것입니다.
본 입문 과정에서 생략된 것은,
SQL DDL 중에서 CREATE TABLESPACE, ALTER TABLESAPCE, CREATE USER, ALTER USER, DROP USER, GRANT, REVOKE 등 주로 DBA가 담당하는 것들과,
DML 중에서는 다른 DB의 레코드를 검색하는 SELECT(UPDATE, INSERT,DELETE) ∼ FROM 테이블@DB 형식의 문장 등이 있습니다.
그 외에 SUBSELECT에 대해서도 충분한 실습이 없었고, 함수에 대해서도 기본적인 것만 다뤘습니다.
오늘 다루는 VIEW와 관련해서도 CREATE VIEW 외에 DROP, SELECT, UPDATE, INSERT INTO, DELETE 등에 대해서는 다루지 않았습니다.
백업 및 복구와 관련된 내용, SQL 편집 명령 등에 대해서도 다루지 않았습니다.
만약 기회가 된다면 위의 내용들로 오라클(SQL) 중급 강좌를 한번 진행했으면 하는 생각입니다.
그럼 DB 입문 마지막 시간, CREATE VIEW 학습을 시작합니다.
VIEW는 오라클에서 제공하는 가상의 테이블(Virtual Table)입니다. 이미 우린 여러 실습을 통해 실제 테이블을 만들고 검색하는 일들을 해봤습니다. VIEW는 실제 테이블을 바탕으로 만들어진 가상의 테이블이며, 검색 등 기타 사용법은 실제 테이블과 거의 유사합니다.
따라서 이번 시간에는 VIEW를 만드는 방법을 주로 다루기로 하고, 기타 데이터 검색, 삭제, 변경 등은 실제 테이블로 작업하는 것과 거의 동일하므로 따로 설명하지는 않겠습니다.
- VIEW 만들기
CREATE OR REPLACE VIEW view_name
AS query
[WITH CHECK OPTION]
[WITH READ ONLY];
참고로 만들어진 VIEW를 삭제하려면,
DROP VIEW view_name; 라고 하면 됩니다.
뷰를 만들 때 CREATE OR RELPACE VIEW 대신 그냥 CREATE VIEW만 사용해도 됩니다. 그러나 그냥 CREATE VIEW를 통해 만들어진 뷰의 구조를 바꾸려면 뷰를 삭제하고 다시 만들어야 되는 반면, CREATE OR REPLACE VIEW는 새로운 뷰를 만들거나 기존의 뷰를 통해 새로운 구조의 뷰를 만들 수도 있습니다. 그래서 대부분 뷰를 만들 때는 CREATE VIEW 대신 CREATE OR REPLACE VIEW를 사용하는 편입니다.
- VIEW에는 VIEW를 생성하는 SELECT 문만 저장됩니다. 즉 실제로 테이블은 존재하지 않으며, VIEW를 SELECT 문으로 검색하는 순간 실제 테이블을 참조하여 보여줍니다.
- VIEW의 query문에는 ORDER BY 절을 사용할 수 없습니다.
- WITH CHECK OPTION을 사용하면, 해당 VIEW를 통해서 볼 수 있는 범위 내에서만 UPDATE 또는 INSERT가 가능하합니다.
예를 들어,
CREATE OR REPLACE VIEW V_EMP_SKILL
AS
SELECT *
FROM EMP_SKILL
WHERE AVAILABLE = 'YES'
WITH CHECK OPTION;
위와 같이 WITH CHECK OPTION을 사용하여 뷰를 만들면, AVAILABLE 컬럼이 'YES'가 아닌 데이터는 VIEW를 통해 입력할 수 없습니다. 즉, 아래와 같이 입력하는 것은 '불가능'하다는 것입니다.
INSERT INTO V_EMP_SKILL
VALUES('10002', 'C101', '01/11/02','NO'); - WITH READ ONLY을 사용하면 해당 VIEW를 통해서는 SELECT만 가능하며 INSERT/UPDATE/DELETE를 할 수 없게 됩니다. 만약 이것을 생략한다면, 뷰를 사용하여 Create, Update, Delete 등 모두 가능합니다.
- VIEW에는 VIEW를 생성하는 SELECT 문만 저장됩니다. 즉 실제로 테이블은 존재하지 않으며, VIEW를 SELECT 문으로 검색하는 순간 실제 테이블을 참조하여 보여줍니다.
- VIEW 만들기 실습
EMP_SKILL 테이블과 SKILL 테이블의 EMP_NUM, SKILL_NO, SKILL_NAME 컬럼을 볼 수 있는 뷰(V_EMP_SKILL2) 만들기
CREATE OR REPLACE VIEW V_EMP_SKILL2
AS
SELECT A.EMP_NUM, A.SKILL_NO, B.SKILL_NAME
FROM EMP_SKILL A, SKILL B
WHERE A.SKILL_NO = B.SKILL_NO; - VIEW 검색 실습
위에서 만든 V_EMP_SKILL2 뷰의 내용을 검색하려면 일반 테이블을 검색하듯이 다음과 같이 하면 됩니다.
SELECT * FROM V_EMP_SKILL2;
이상으로 DB 입문 강좌를 모두 마칩니다.
'IT > SQL' 카테고리의 다른 글
| [SAS]Update와 merge 비교 (0) | 2017.03.23 |
|---|---|
| 1. SAS EG 시작하기 - 데이터를 SAS 데이터셋으로 가져오기 (0) | 2016.12.20 |
| Mysql 기본과정을 배울 수 있는 자료/사이트 (0) | 2016.10.31 |
| Join의 종류 (0) | 2016.10.24 |
| 2일차 - 테이블생성하기, 검색기능만들기 (1) | 2016.10.24 |
| 1일차 - 웹서버, FTP서버, db서버 생성하기 (0) | 2016.10.22 |
| [mysql] 테이블 컬럼 추가,삭제,변경하기 (0) | 2016.08.23 |